
Sobre el problema de la implementación de funciones de base de datos «Fan Out» – parte IV
En la parte I hemos introducido el problema de la función DB en abanico, y pensamos que cada función de este tipo es en realidad una multifunción con 2^n versiones, dadas n entradas. En la parte II, hemos visto algunas soluciones al problema en cuestión. En la parte III presentamos algunas técnicas de metaprogramación de plantillas y algunas clases que servirán como bloques de construcción y nos ayudarán a comprender la solución que se presentará en esta parte. Además de explorar la solución, también presentaremos un punto de referencia para compararlo con algunas de las otras soluciones que hemos mostrado durante este artículo de varias partes. Terminaremos conectándolo de nuevo al tema con el que comenzamos: bases de datos (o motores ETL, (Extract, transform, and load)). Como siempre, intentaré ofrecer una explicación sobre los temas modernos de C++ que vayan surgiendo (al menos desde mi perspectiva). Hay mucho que cubrir en esta última parte … ¡así que comencemos!
Introducimos el concepto, el uso y la potencia de SuperFunctor
En el artículo anterior, presenté la estructura FunctorInputSetter, con su estructura contenedora FunctorInputSetterWrapper. Recordemos: dada una tupla de entradas y un número de versión (máscara) entre 0 y el tamaño de la tupla – 1, uso esta máscara para obtener una nueva tupla de la misma longitud. El bit #i en la máscara decide para el i-ésimo elemento en la tupla – tipo T, si se debe incluir T en la tupla de resultado (es decir: T representa un elemento de entrada constante) o incluir std :: vector <T> en él (es decir: T representa un elemento de entrada de vector). La tupla de entrada y el número de versión representan una entrada de función escalar y el número de versión multifunción, respectivamente. La salida representa la entrada correcta para esa versión de la multifunción. Ahora nos gustaría usar esa estructura para lograr lo siguiente:
- Toma una función, como subString con una firma (signature) (escalar) de string subString (string, int, int), y diseña una clase de superfunctor que implemente todas las versiones 2 ^ 3 = 8 de la función, usando una máscara que decida el número de versión.
- Todas estas diferentes implementaciones deben crearse en el momento de compilación, ser efectivas y, lo más importante, escribirse una sola vez y ejecutarse «polimórficamente» para todas las versiones.
Ahora, creo que eso ya suena como una tarea difícil, pero ¿es suficiente? Supongamos que tenemos este código «mágico» y que contiene sólo 30-40 filas de código. Así que tendremos una clase SubString dedicada con una versión escalar de subString y 30-40 líneas de plantilla de código de metaprogramación que «fabrica» las 8 versiones diferentes de esta multifunción. Bueno, impresionante, pero ¿qué pasa con la función concat? o Plus? ¿Y con toDate? ¿Y con las otras 250 multifunciones de la base de datos? ¿Debería estar incrustada cada una de ellas en su propia clase e incluir este código TMP «mágico» de 30-40 líneas? Si hemos aprendido la lección de TMP, la respuesta es no. ¡Podemos hacer que el código «mágico» sea aún más mágico usando más TMP y así evitar el código repetitivo de cada clase multifunción! ¡Crearemos una clase única que nos ayudará a implementar todas las funciones múltiples y todas sus versiones! ¡Llamaremos SuperFunctor a nuestra clase basada en TMP!
Antes de presentar la solución completa, echemos un vistazo a su uso. Me gustaría mostraros lo simples que pueden ser las cosas gracias a esa solución. ¿Recuerdas el código de subString largo y complejo que vimos tanto en MonetDB como en ClickHouse en la parte II? ¿Recuerdas la horrible repetición de código que vimos en estas soluciones (y también en la solución más simple presentada primero)? Ten en cuenta: era solo para subString. Ahora imagina este tipo de código para 250 funciones de base de datos y tendrás un lío perfecto que mantener. Ahora echemos un vistazo al uso de SuperFunctor para subString. Primero, implementamos la versión básica escalar de subString:

Ahora veamos la inicialización de las 8 versiones del SuperFunctor de subString:

Lo que tenemos aquí es la declaración de 8 versiones diferentes de subString, siendo substringFunctorX la versión #x de la multifunción subString, como se presenta en la tabla de verdad en la parte III de este artículo.
Por ejemplo: substringFunctor4 es la versión de subString con la firma de entrada multifunción de (string, int, vector<int>), como sugiere 4 = 0b100. En la imagen anterior podemos ver cómo pasamos la subcadena de la función escalar como un argumento a la función de plantilla createSuperFunctor y usamos la máscara como un parámetro de plantilla explícito (8 máscaras en total). Pronto veremos cómo y por qué se usa esta sintaxis, pero antes de eso, estemos de acuerdo en que esto es bastante simple.
Ahora, veamos el uso de estas diferentes versiones de superfunctor. Para ello supongamos que tenemos 3 variables constantes declaradas así (presta atención al índice y tipo de cada uno, como en la tabla de verdad):

y 3 variables vectoriales (nuevamente – índice y tipo como en la tabla de verdad):

(el código en mi git incluye el ejemplo completo, incluida la inicialización del vector de entrada). Por ahora, centrémonos en el uso de las diferentes 8 versiones que creamos anteriormente:
Presta mucha atención: cada versión utiliza las variables «correctas», ya sea un vector o un escalar, en cada uno de los 3 parámetros de función. Estas se colocan dentro de una llamada de función (los objetos functor tienen una función operator()) que llama a la versión multifunción de forma muy natural, cada llamada con su propia versión. Puede ser que estas llamadas te recuerden al ejemplo más simple que mostramos en la parte I del artículo. Allí usamos 8 funciones aisladas y sobrecargadas (sin plantillas) que básicamente duplicaron todo el código (cada vez con una firma diferente y un bucle un poco distinto dentro). Por lo tanto, ten en cuenta que las llamadas a funciones en nuestra solución son tan simples como las de la solución más simple. Todo lo que se necesitaba es declarar los functores anteriores, usando la función de fábrica createSuperFunctor con la máscara como argumento de plantilla y la función escalar como parámetro de la función.. ¡Entonces podríamos usar las 8 versiones de forma muy natural!
Además, si nos confundimos, al intentar llamar, por ejemplo, subStringFunctor7 con 1 parámetro no vectorial como ese: res7 = substringFunctor7 (param1, param2, constant1), inmediatamente obtenemos un error de compilación: «error: no coincide con la llamada a ‘(SuperFunctor … «.
Paremos un momento para asimilar esto:
¡El compilador nos “protege” de llamar a cualquiera de las 8 versiones fabricadas automáticamente con parámetros incorrectos (cualquiera de las 3)!
Increíble. Imagínese el gran poder de tener de su lado: un compilador de C ++! Esto podría resultar muy útil en múltiples funciones múltiples con más de 3 parámetros, ¿verdad?
Más adelante, discutiremos brevemente cómo el código anterior podría usarse claramente dentro de un catálogo de base de datos que registrará fácilmente todas estas versiones de manera más efectiva que las 8 filas que se muestran arriba (que no son tan malas de todos modos).
La implementación de la clase SuperFunctor
Ahora, presentamos la implementación completa de SuperFunctor e intentamos explicar sus partes principales:

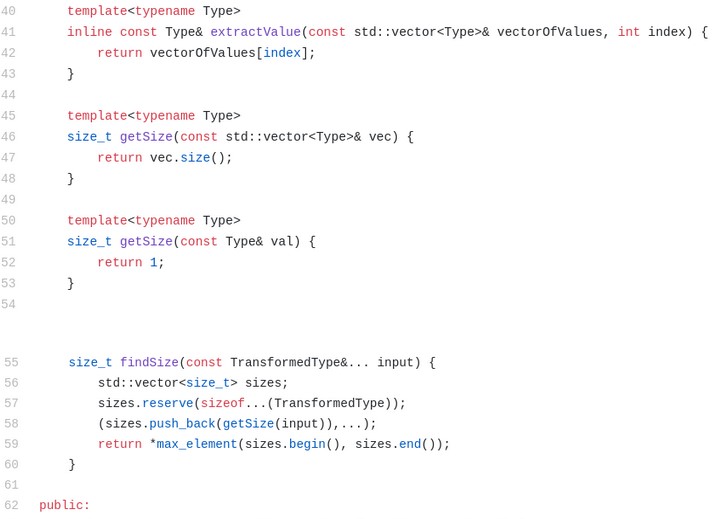
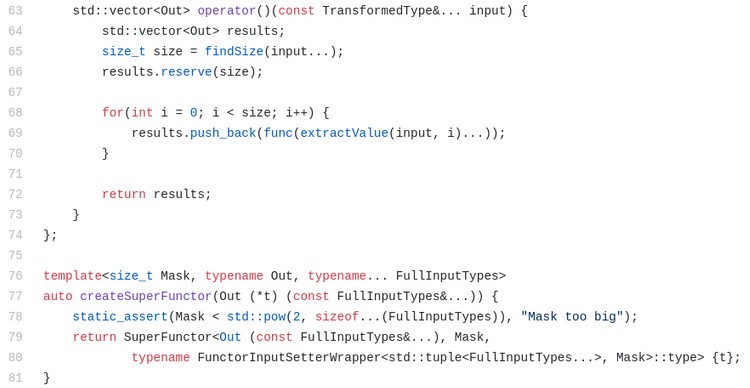
Método auxiliar createSuperFunctor
Primero, echa un vistazo a las líneas 76-81. Allí definimos una función auxiliar que nos ayudará a construir el SuperFunctor más fácilmente (más sobre funciones auxiliares en C++, su función anterior a C++ 17 y por qué las he usado a continuación). La función createSuperFunctor está basada en 3 parámetros:
1. Mask (mascara) (ya hemos visto esto).
2. Out (fuera) que es el tipo de parámetro de salida de la multifunción db (por ejemplo: std :: string para subString).
3. FullInputTypes (Tipos de entrada completos), que en este caso es la lista de tipos variadic de la versión escalar de la multifunción (por ejemplo: string, int, int, en el caso de subString).
Para obtener Mask, lo indicamos explícitamente en la llamada a la función, como en: auto substringFunctor2 = createSuperFunctor<0b010>(subString); (Mask=0b010).
Los otros 2 parámetros de la plantilla se obtienen utilizando la deducción del tipo de función de la plantilla del argumento de la función (más sobre eso en la sección «Métodos auxiliares y CTAD» a continuación). Cuando declaramos un argumento de función: Out (*t) (const FullInputTypes&…), le decimos al compilador que esperamos una función que devuelva Out como su tipo de retorno y obtenga los tipos en la lista de plantillas variadas (FullInputTypes) como entrada. Por supuesto, esto es mucho más simple que escribir explícitamente todos estos parámetros de plantilla. Esta función básicamente realiza dos cosas:
1. En la línea 78 – afirmación estática en el tamaño de la máscara – se verifica en el momento de la compilación que el tamaño de la máscara no sea mayor de lo que debería ser. (no más de 2 ^ n – 1, donde n es la longitud del tipo de plantilla variadic). Más detalles sobre esto en la siguiente sección.
2. En las líneas 79-80 usamos la plantilla de clase presentada en la parte III de este artículo: FunctorInputSetterWrapper. Hacemos uso de esta clase para transformar la lista de tipos «escalares» en FullInputTypes en una forma «vectorizada» de acuerdo con el valor de Mask, como he explicado anteriormente. De esta forma, podemos suministrar (supply) a la clase SuperFunctor definida en las líneas 22-74, el parámetro de plantilla variadic TransformedType que necesita (ver más abajo). Por tanto en las líneas 79-80, llamamos a SuperFucntor con una lista de plantilla explícita completa y especificada (los 3 tipos), y pasamos la función escalar t como parámetro al constructor (La misma t que tenemos en la línea 77 como parámetro.).
Clase SuperFunctor
Ahora, centrémonos en la definición de SuperFunctor en las líneas 22-74. Como antes, usamos un tipo general con 3 tipos de parámetros de plantilla en las líneas 22-23, y luego declaramos una especialización específica en las líneas 25-74. La clase está basada en 3 parámetros de tipo (T, Mask & S), que se especializan en 4 tipos de plantillas: Out (como arriba), FullInputTypes de tipo variadic (tipos de función escalar, como se explicó anteriormente), Mask y otro tipo variadic, TransformedType (la versión vectorizada y transformada de FullInputTypes, como se explicó anteriormente). Obtenemos los valores para los 4 tipos por la especialización en la línea 26:
1. Out & FullInputTypes se deducen al hacer coincidir la expresión Out (const FullInputTypes & …) con la firma de la función escalar real pasada en la línea 79 (que se relaciona con T en la línea 22). He declarado este tipo de función como Func en la línea 28 por conveniencia (la sintaxis es un poco diferente a la del parámetro de plantilla en la línea 26, pero esta es simplemente la sintaxis de C++).
2. Mask se da explícitamente (está relacionado con el tipo Mask en la línea 22).
3. El tipo variadic TransformedType se da dentro de un std :: tuple (std::tuple<TransformedType…>). Está relacionado con el tipo S en la línea 22.
Ahora repasemos el resto de la clase rápidamente:
- El constructor en la línea 30, usa la definición Func de arriba, para obtener la función escalar real como parámetro f. Se mantiene esa función como un campo privado (declarado en la línea 33).
2. Se utilizan 2 funciones con plantilla llamadas getSize en las líneas 45-53 para devolver el tamaño del vector (línea 47) o el tamaño del escalar (que siempre es 1, línea 52).
3. La función findSize en las líneas 55-60 se utiliza para obtener el tamaño de entrada. Sí, podríamos obtenerlo como otro parámetro para operator() a continuación, pero he pensado que sería bueno deducirlo yo mismo sin preocupar al usuario. Esta función encuentra el tamaño de cada elemento en la entrada (indicado por TransformedType) y lo inserta en un vector de tamaños (cada una de las entradas se envía a la función de plantilla getSize, utilizando la función de expresión de pliegue (fold expression) de C++17 en el retroceso del vector (vector‘s push_back) presentado en la parte III). Luego, devuelve el elemento máximo de este vector, que representa el tamaño de todos los vectores en la entrada (si solo hay escalares, el superfunctor devolverá un vector de tamaño 1 con la función escalar aplicada en la entrada escalar).
4. 2 funciones con plantilla extractValue en las líneas 35-43 se utilizan para abstraer la funcionalidad de extraer el valor del índice i de cualquiera de las entradas (ya sea un vector o un escalar), que se pasa como parámetro a cada función. Por tanto, para un vector (línea 46) simplemente devuelve el valor en el índice dentro del vector, mientras que para un escalar (línea 37) simplemente devuelve el valor constante (ignorando el valor del índice).
5. El único método público es operator() (como es habitual con los objetos functor) en las líneas 63-73. De esta manera podemos usar el functor como una función simplemente (e.g.: subStringFunctor7(param1, param2, param3)). Esta función define un vector de resultados usando el tipo Out (línea 64) y luego encuentra el tamaño de entrada usando findSize (línea 65). Luego usa un bucle foreach sofisticado en la línea 68-70 para llamar a la función escalar (que se encuentra en la función de campo privado) en cada «fila» de la entrada. Para cada índice i, esta función ejecuta la función extractValue con plantilla en cada uno de los tipos de entrada por sí misma. Lo hace usando la función de expresión de pliegue sobre la entrada de variable, de tipo variadic TransformedType. Luego, ejecuta func (que es la función escalar) en los resultados de todas las llamadas a extractValue, aplicando así la función escalar en todos los valores «escalares», extraídos de todas las entradas. El resultado se envía inmediatamente al vector de resultados. ¡Todo esto sucede en la línea 69, que es lo más destacado de esta solución! Impresionante, ¿no? A continuación, el vector de resultado se devuelve al que la ha llamado (caller).
Como prometí: solo implementamos la funcionalidad de la multifunción una vez (solo en la función escalar), ¡y luego creamos un superfunctor para ella! Sin duplicación de código en absoluto, y ni siquiera es necesario escribir ese superfunctor para cada multifunción.
Se escribe una vez y se ejecuta en todas partes: para cada función, en todas sus versiones. ¡Fenomenal!
Nota: El uso de funciones de plantillas privadas dentro de la solución no alarga demasiado el código generado: se crean en tiempo de compilación y cada una tiene un máximo de n versiones con n = tamaño de entrada variable.
Aserción estática en el tamaño de la máscara (+ error de compilación en una máscara demasiado grande)
Me gustaría enfatizar otro de los beneficios que obtenemos al usar TMP. Echando otro vistazo a la inicialización de los functores anteriores, usando createSuperFunctor con la máscara (Mask) adicional, se podría argumentar, y con razón, que podríamos cometer un error al escribir la máscara. Vimos anteriormente que el compilador nos protege de llamar a cualquiera de las 8 versiones con parámetros incorrectos. Adivina qué, ¡también puede evitar que inicialices tu clase con una máscara incorrecta! Para eso usamos la aserción estática en la línea 78. Calculamos un valor constante en tiempo de compilación, que en el caso de subString, es igual a 2^3 = 8 (usando std :: pow con 2 como base y el tamaño de la entrada variable de la función como coeficiente). De esta manera limitamos Mask a ser menor que 8 (0 – 7). Si quisiéramos (yo no he agregado eso), podemos afirmar que Mask > = 0. El código no se compilaría de todos modos, pero creo que usar una máscara negativa es menos probable que usar un valor de máscara que está «fuera de límite» (lo que podría suceder fácilmente). En realidad, si lo piensas, usar superfunctor con Mask = 0 también es redundante, ya que ya implementamos la versión escalar de todos modos, por lo que realmente no importa (aunque lo admitimos). Entonces, volviendo al límite superior, si usamos incorrectamente el valor de máscara de 8 = 0b1000 así: auto myFunctor8 = createSuperFunctor<0b1000>(subString), inmediatamente obtendremos un error de compilación con el mensaje de error: «error: la aserción estática falló: la máscara es demasiado grande». Gracias compilador, ¡has sido de gran ayuda, amigo!
Métodos auxiliares y CTAD
Un lector astuto podría haberse preguntado sobre el uso del método auxiliar createSuperFunctor en la línea 77. ¿Para qué lo necesitamos? ¿Por qué no podemos simplemente llamar a SuperFunctor directamente sin esta llamada intermedia? Vamos a sumergirnos un poco en el C ++ moderno. Antes de C++17, siempre tenías que especificar todos los parámetros de la plantilla para una plantilla de clase de forma explícita. En aquel entonces, C++ no tenía soporte para la deducción automática de parámetros de plantilla de clase de los argumentos pasados al constructor de plantilla de clase. Sin embargo, las plantillas de función siempre han admitido la deducción automática de parámetros de plantilla en función de los argumentos pasados a la plantilla de función. Por ejemplo, la plantilla de clase std :: pair puede contener 2 valores de diferentes tipos. Hasta C ++ 17, si quisiéramos iniciar un std :: pair <int, double> tendríamos que elegir una de estas opciones:
- Especificar explícitamente todos los parámetros de la plantilla en la definición de tipo std::pair<int, double> pair1(2, 3.4);.
- Evitar la especificación explícita de todos los parámetros de la plantilla utilizando una función auxiliar llamada std :: make_pair (). Esta función «disfruta» de la deducción automática de los parámetros de la plantilla en función de los valores pasados (como cualquier función), por lo que podemos escribir fácilmente: auto pair2 = std :: make_pair (2, 3.4). Siempre y cuando los valores reales estén bien definidos (por ejemplo: 2 no se puede traducir a int y a short a la vez), esto funcionaría.
Ahora, con C ++ 17 tenemos una nueva característica llamada CTAD – deducción de argumento de plantilla de clase (class template argument deduction). El compilador ahora deduce automáticamente los parámetros del tipo de plantilla basándose en los argumentos pasados al constructor. Entonces ahora podemos escribir simplemente: std::pair pair3(2, 3.4);.
Por lo tanto, estas funciones auxiliares ya no son necesarias. ¿O sí?
Primero, todavía los encontramos con las funciones de ayuda de puntero inteligente (smart pointer helper functions) std::make_unique & std::make_shared (si pasas una T * a sus constructores, el compilador tendría que elegir entre deducir <T> o <T []> … no es suficientemente bueno, supongo). En términos generales, CTAD funcionaría solo cuando todos los parámetros de la plantilla de una plantilla de clase pudieran deducirse de los parámetros del constructor o tener un valor predeterminado en la definición de la clase de la plantilla. En nuestro caso declaramos una plantilla de clase con parámetros de varias plantillas:

pero requerimos que nuestra inicialización sea muy simple:auto substringFunctor2 = createSuperFunctor<0b010>(subString). Por tanto, queríamos proporcionar solo la máscara (Mask) como parámetro de plantilla explícito, y todos los demás parámetros de plantilla se deducirían automáticamente de la función escalar pasada como parámetro. Desafortunadamente esto no se puede hacer incluso con la poderosa función de CTAD, ya que se quedan sin inicializar demasiados parámetros de plantilla desconocidos. Tenemos que usar el método de ayuda simple (helper method) para ello, ya que su deducción de tipo todavía es mucho más capaz que la deducción de plantilla de clase (no estoy seguro de por qué. Discusión interesante en Stackoverflow …).
Algunas cifras de referencia: examina la perspectiva del rendimiento
Como se discutió en la parte II de este artículo, hay soluciones mucho más simples para el problema. Claro, tienen sus desventajas (y muchas de ellas, como vimos), pero algunas de ellas, especialmente la simple y codificada, podrían servir como base para lo que podríamos esperar de la implementación multifunción desde la perspectiva del rendimiento. Como he mencionado anteriormente, podría ser un ejercicio «académico» «muy agradable» para resolver este problema con TMP (esta es la forma común en que la mayoría de los profesionales tratan TMP de todos modos). Este no era mi propósito aquí.
Me gustaría presentar esa solución como una solución alternativa al problema en una base de datos de alto rendimiento o motor ETL. Por lo tanto, eso no nos será de mucha utilidad si la solución es mucho más lenta que la solución de referencia.
Para ayudar a poner la solución presentada en una perspectiva de rendimiento, he hecho algunas pruebas de referencia básicas (benchmark tests). Estas no son las pruebas habituales que habría realizado para la evaluación comparativa. El propósito aquí no era optimizar la solución subString al máximo. Para hacer eso, necesitaremos:
- Optimizar la función escalar subString utilizada en todas las soluciones (muy importante). Esta función se ejecuta millones de veces en una entrada vectorial de varios millones de filas.
- Ejecutar todas las soluciones de una manera multiproceso (multi-threaded), ya que no hay dependencia entre la fila i y la fila j para i! = j. Es una solución básica para mapear la entrada a múltiples subprocesos en paralelo (no hay una reducción real aquí) y terminar la tarea mucho más rápido. Nada nuevo aquí: lo he hecho docenas de veces antes mientras implementaba nuevas funciones en una base de datos a gran escala.
Bueno, este no es el propósito de este punto de referencia. Cualquier solución que hayamos visto podría equipararse fácilmente mediante el uso de un enfoque de múltiples subprocesos / tareas, y cualquiera de ellos se beneficiará de la misma manera de una implementación de subString escalar más rápida (ya que todos lo usan la misma cantidad de veces). El propósito del punto de referencia es mostrar que la aplicación de la solución TMP, en lugar de la solución de referencia, no solo nos beneficiará de las perspectivas funcional, de reutilización de código, de prueba (y otras), pero que también es un gran concursante desde la perspectiva de la rendimiento. Es decir, es una solución muy eficaz que no descartarás al considerarla ni como una solución al problema en una base de datos real, o ni al considerarla como «puramente académica». Lo único que «tienes que pagas» es el tiempo dedicado a aprender las técnicas de TMP y a aplicarlas.Creo que es un precio razonable.
En este punto de referencia, he analizado las 4 soluciones discutidas hasta ahora:
- La solución de referencia: la que presentamos en la parte I. Es básicamente lo que se hizo en las dos bases de datos que analizamos en la parte II. (Es decir, todas las versiones usan el mismo bucle for en diferentes vectores y llaman a la versión escalar en cada fila).
2. La solución «parametrizada» que se muestra en la Parte II – Parámetro de clase de plantilla (templated class Paramater).
3. Una variante de Parameter que usa std :: variant – la clase Parameter2 presentada en la parte II.
4. Nuestra nueva y brillante solución TMP 
He ejecutado todas las soluciones en la versión de todos los vectores de subString (obteniendo 3 vectores como entrada) con un tamaño de entrada de 50M. Se ejecutó en mi computadora portátil con un solo subproceso. Como he discutido previamente, los números absolutos que se presentan a continuación no son importantes. Lo importante son los tiempos de ejecución relativos entre las soluciones y la solución de referencia (por lo tanto, no importa cuál es la especificación de CPU de mi ordenador portátil y el hecho de que lo ejecuto en un solo hilo). Aquí están los resultados de la versión «subString7″:

Podemos observar que ambas soluciones parametrizadas son demasiado lentas: la primera añade solo +26.77% al tiempo de ejecución en comparación con la solución simple de referencia (aún alta), y la segunda es «exagerademante» lenta (+142.27% de tiempo de ejecución). Por lo tanto, ambas son “inimaginables» como alternativa de mejor rendimiento a la solución simple. Pero observa lo siguiente:
¡Nuestra nueva solución TMP solo añade un 1.5% al tiempo de ejecución de la solución de base!
Creo que este análisis muestra que, desde la perspectiva del rendimiento, la nueva solución al menos vale la pena. También quiero mencionar que los resultados son consistentes y mantienen la misma proporción en entradas más grandes (sin disminución del rendimiento en ninguna solución en entradas más grandes).
Para concluir esa sección, examinemos una comparación similar, más pequeña, de ambas soluciones en la versión «subString1«, es decir: la versión de subString con un vector de cadena y 2 enteros escalares. Aquí, las brechas aumentan al 4% -5% (aún no tan mal). La razón de esto es simple: «la ventaja» de la solución básica sobre la solución TMP es que para cualquier fila tiene «acceso directo» a los valores de los parámetros (ya sean vectoriales o constantes), mientras que la solución TMP siempre debe usar 3 llamadas a la función extractValue para extraer el valor «polimórficamente» de un vector o una constante. Cuando todas las entradas son vectores, esta diferencia es menor (porque el acceso vectorial todavía requiere acceso especial a la memoria para múltiples celdas, incluso si son consecutivas). Sin embargo cuando se usan constantes, la solución básica usa una celda de memoria única que contiene el valor constante (que probablemente sea accesible a través de la caché L1 durante todo el cálculo), mientras que la solución TMP usa una llamada de función cada vez. Esto es menos efectivo. No es tan crítico, porque esta diferencia del 4 al 5 por ciento también se mantiene en entradas más grandes (por lo que tiene un límite). Por supuesto, no descarta esa solución.
Algunas palabras sobre el desarrollo con TMP
El desarrollo de una solución en TMP es periódico. Todas mis soluciones tuvieron algunos ciclos de desarrollo: cada una mejora / optimiza un poco la anterior. La solución presentada aquí no fue escrita así de inmediato (de ninguna manera José …). ¡Seguí encontrando implementaciones cada vez mejores incluso mientras escribía este conjunto de artículos! Así que mi mensaje al desarrollador amateur de TMP:
No te rindas cuando algo no funcione o no se compile, ¡Sucede muchas veces, vuelve a intentarlo!
Posible uso en un catálogo de bases de datos
Como he mencionado más de una vez, creo firmemente que esta solución se puede integrar de forma eficaz en un sistema de gestión de base de datos real. Una parte importante de cualquier DBMS es el catálogo de bases de datos. Este catálogo generalmente declara qué tipo de tipos de datos puede manejar la base de datos y qué funciones admite. En términos generales, una base de datos tendrá una consulta DSL (por ejemplo: SQL) que utilizará una sintaxis dedicada con extensiones de función. Cada vez que un usuario escribe una consulta con una función, el parser (analizador sintáctico) analizará la consulta y comprobará si es válida. En la fase de análisis (parsing phase), generalmente no validamos las funciones, solo nos referimos a ellas como ‘tokens’ o nodos en el árbol de análisis. Posteriormente, antes de crear el plan de ejecución de la consulta, cada nombre de función y sus parámetros se verifican con el catálogo de la base de datos. Solo si la función aparece en la base de datos y con una firma que admita el uso actual de la misma en la consulta, podemos pasar a su ejecución. Para respaldar esa funcionalidad, generalmente hay un módulo en el código que es responsable del registro de la función en el catálogo de la base de datos. Si lo recuerdas, hemos visto una implementación de dicho registro de base de datos en nuestra discusión de MonetDB en la parte II de este artículo.
Antes teníamos la siguiente inicialización de subString:

Este tipo de código en una base de datos generalmente se escribirá de manera un poco diferente. Por lo general, lo encontraremos como parte de 8 llamadas de función diferentes a la función de registro del catálogo db. En nuestro caso, todas estas funciones en realidad se crean durante esta fase (como con cualquier clase de plantilla, debe crearse en tiempo de compilación con todos los tipos relevantes). El código de la imagen anterior parece un poco tedioso. ¿Por qué necesitamos este código «repetitivo» de 8 líneas? Como siempre, debemos preguntarnos si podemos dejar que el compilador se encargue de este trabajo. La respuesta es sí. Podemos usar fácilmente una función de registro con plantilla que obtendrá la función escalar subString como un argumento de función única. Esta función deducirá el número n de parámetros de entrada en esa función escalar y puede generar todas las llamadas a createSuperFunctor necesarias usando valores de Mask de 0 a 2 ^ n – 1. También puede realizar el registro de tipo necesario en sus estructuras de datos internas para admitir la verificación del tipo de entrada y salida de ambas funciones y la verificación del nombre de la función durante la ejecución de la consulta más adelante.
No he agregado este código aquí porque no he implementado un catálogo de base de datos completo y porque esto habría hecho que este artículo fuera aún más largo (no, por favor. El artículo ya es suficientemente largo, estarás de acuerdo :)). Pero, como he mencionado anteriormente, esta solución se puede integrar completamente con un registro de catálogo de base de datos sencillo y sofisticado por un lado, y un procesamiento posterior al análisis de consultas y resolución de funciones por el otro.
En resumen
Bueno, con esto hemos concluido todas las partes del artículo ‘Sobre el problema de la implementación de funciones de base de datos «en abanico». En primer lugar, espero que sigas aquí. Sé que esta parte fue una lectura larga y difícil. Por tanto, si sigues aquí, lo considero un logro y que eres un lector fiel e interesado. Gracias. En segundo lugar, espero haberte convencido de que me he tratado un problema del mundo real, uno que realmente me molestó cuando tuve la tarea de implementar una base de datos o funciones basadas en filas del motor ETL (docenas de ellas). En tercer lugar, espero que hayas podido entender la mayor parte, si no toda, de la solución TMP que he ofrecido y que te haya parecido al menos interesante si no alucinante (no podía esperar eso, por supuesto). Por último, me tomé el tiempo para discutir algunos temas que son puramente temas de bases de datos. También he intentado extender la discusión para incluir algunas de las esquinas del estándar C++ con las que nos hemos encontrado (especialmente las relacionadas con plantillas, plantillas variadas, TMP y deducción de tipos). He introducido algunas técnicas de TMP que utilizan las últimas funciones de C ++ (como las expresiones de plegado) para incitar tu curiosidad y ayudarte eventualmente a comprender la solución SuperFunctor. Espero que la explicación técnica no haya sido demasiado tediosa y no haya faltado ninguna parte importante que sea fundamental para su comprensión. TMP no es fácil de entender, como todos sabemos.
Espero que hayas disfrutado leyendo mis artículos. Por favor, deja un comentario, así sabré que al menos a algunos de vosotros le han resultado interesantes / útiles, y que realmente fueron leídos por un humano y no solo visitados. (Linkedin no da ninguna estadística sobre eso, solo #visitas. Los comentarios humanos son los mejores). Espero escribir más contenido similar pronto. Vuestros comentarios también pueden sugerir posibles temas de discusión o plantear problemas para que investigue y debata en artículos futuros. Por favor comenta. ¡Cualquier comentario será bueno!
Manteneos sanos. Sed amables unos con otros. Gracias a todos.
raducido por : Mireia Alba Kesti Izquierdo