
Guía para principiantes de Athena – Parte 1: Primeros pasos

¿De qué se trata este artículo?
En este artículo, comenzaremos a explorar AWS Athena.
Aprenderás como se crea una consulta.
Este artículo es principalmente para desarrolladores de BI que desean ampliar sus capacidades para gestionar Big Data.
¿Qué es Athena?
Athena es un servicio completo sin servidor que nos da el poder de realizar consultas tipo SQL sobre archivos estructurados y semiestructurados en S3.
Es importante tener en cuenta que los datos no se almacenan en Athena. Athena solo consulta los datos, no los almacena.
Si desea consultar archivos en s3, primero deberías crear una tabla:
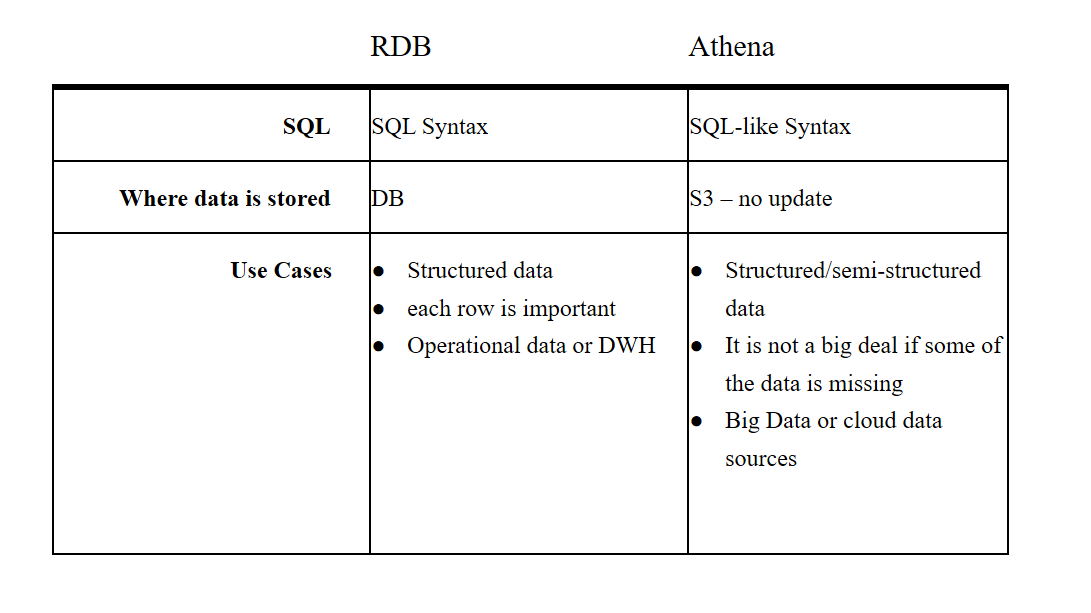
Primeros Pasos
Primero necesitamos una cuenta de AWS para usar sus servicios.
** Si ya tiene una cuenta, pase a la siguiente sección.
- Abre tu navegador
- Ingrese https://aws.amazon.com/
- Haga clic en «Crear una cuenta de AWS»
- Introduce tu correo electrónico y contraseña
- Haga clic en «Continuar»
- Ingrese su información de contacto
- Marque la casilla «Marque aquí para indicar que usted …»
- Haga clic en «Crear cuenta y continuar»
- Ingrese su «Información de pago»
- Haga clic en «Verificar y agregar»
- Finalice el proceso «Confirme su identidad»
- Seleccione el plan básico gratuito
- Es decir, tiene una cuenta de AWS
- Inicia sesión en la consola
En segundo lugar, subimos nuestro fichero a S3
- Vaya a S3 y haga clic en «Create bucket»
- Ingrese su nombre de cubo y elija la región
- Haga clic en los “Next”
- Haga clic en «Create Bucket»
Ahora verías tu bucket
- Haz clic en tu bucket
- Haga clic en «Crear carpeta»
- Asigne un nombre a la carpeta «Ejemplo_financiero» y haga clic en «Guardar»
- Suba el archivo Ejemplo_financiero a su nueva carpeta
- Puedes encontrar el archivo aquí.
Crear una tabla
- Haz clic sobre “Connect data source”
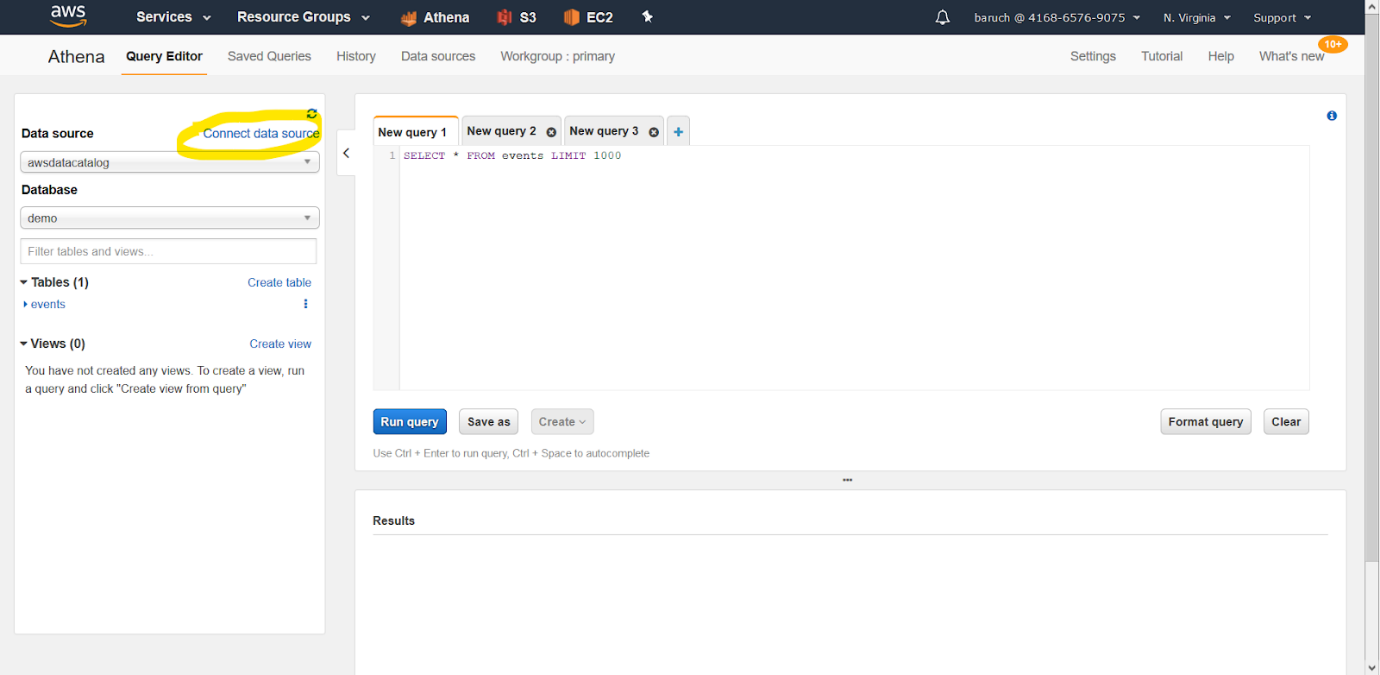
- Seleccione, las opciones “Query data in Amazon S3”, “AWS Glue data catalog”
- Haz clic en “Next”
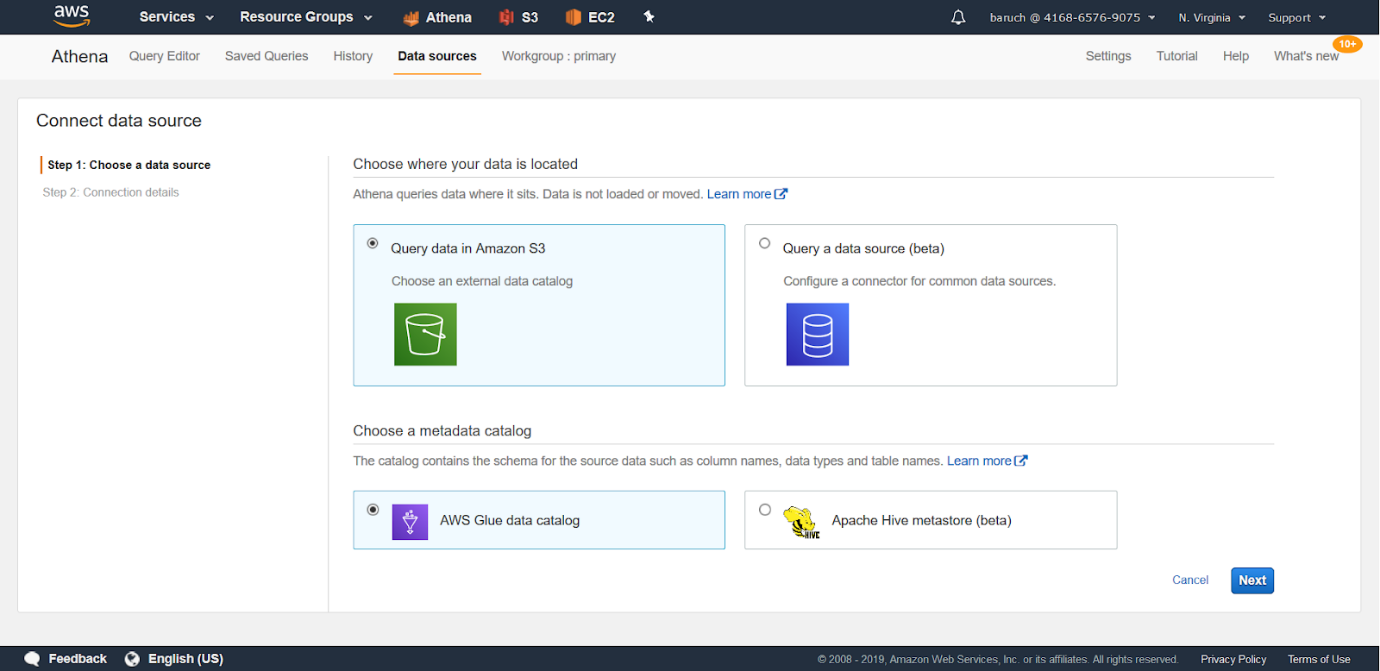
- Y luego tienes que elegir lo siguiente:
- Usar AWS Glue en S3
** Glue es un servicio de AWS que crea esquemas automáticos basados en archivos.
** Es una manera excelente de automatizar las cosas si se le han otorgado los permisos correctos.
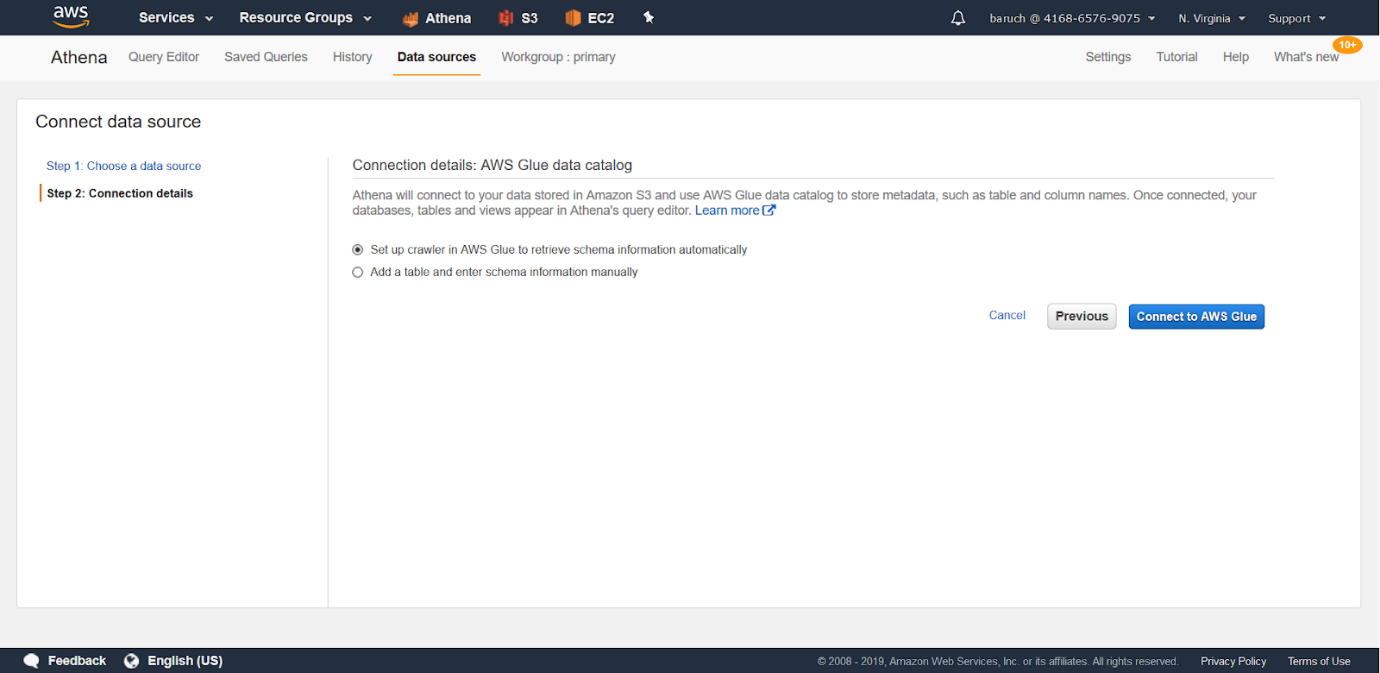
- Cree una tabla manualmente (genere un script similar a SQL).
- Elija la opción manual y haga clic en «Siguiente», que lo llevará a esta pantalla:
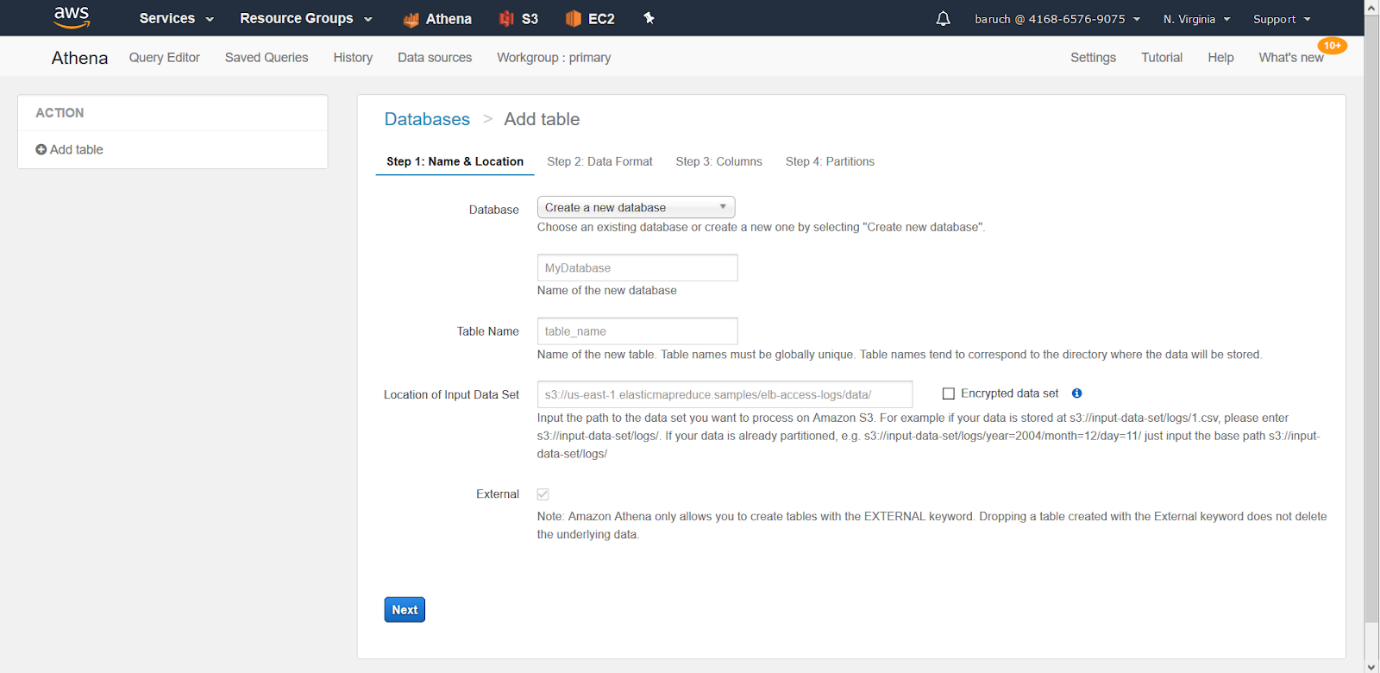
- Elija su base de datos (o cree una nueva)
- Elija un nombre de tabla y la carpeta a la que se conectará su tabla (la carpeta que creamos anteriormente) y haga clic en “Siguiente”.
** tenga en cuenta la viñeta externa, que está seleccionada y no se puede cambiar.
La razón de esto es que no podemos insertar datos en Athena. Athena no guarda ningún dato, solo metadatos. No hay cláusula de inserción en Athena. (Sin embargo, hay una inserción en s3.)
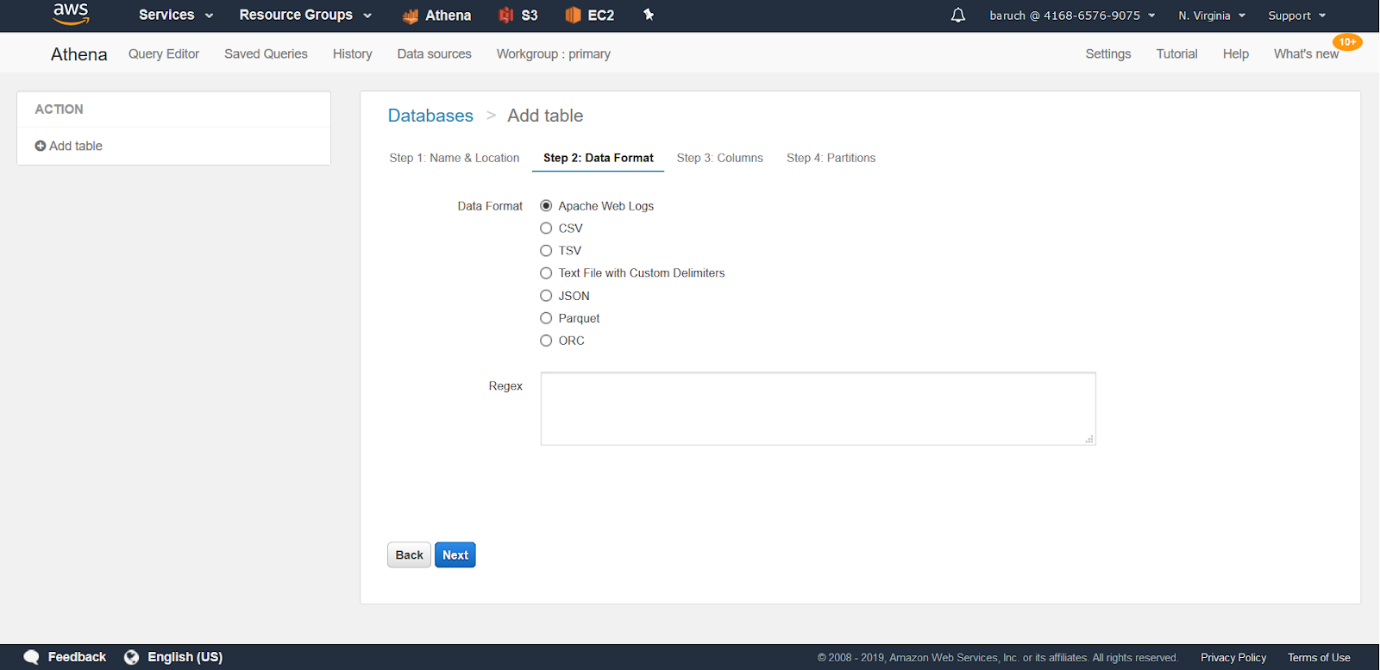
- Elija CSV / JSON y haga clic en «Siguiente»:
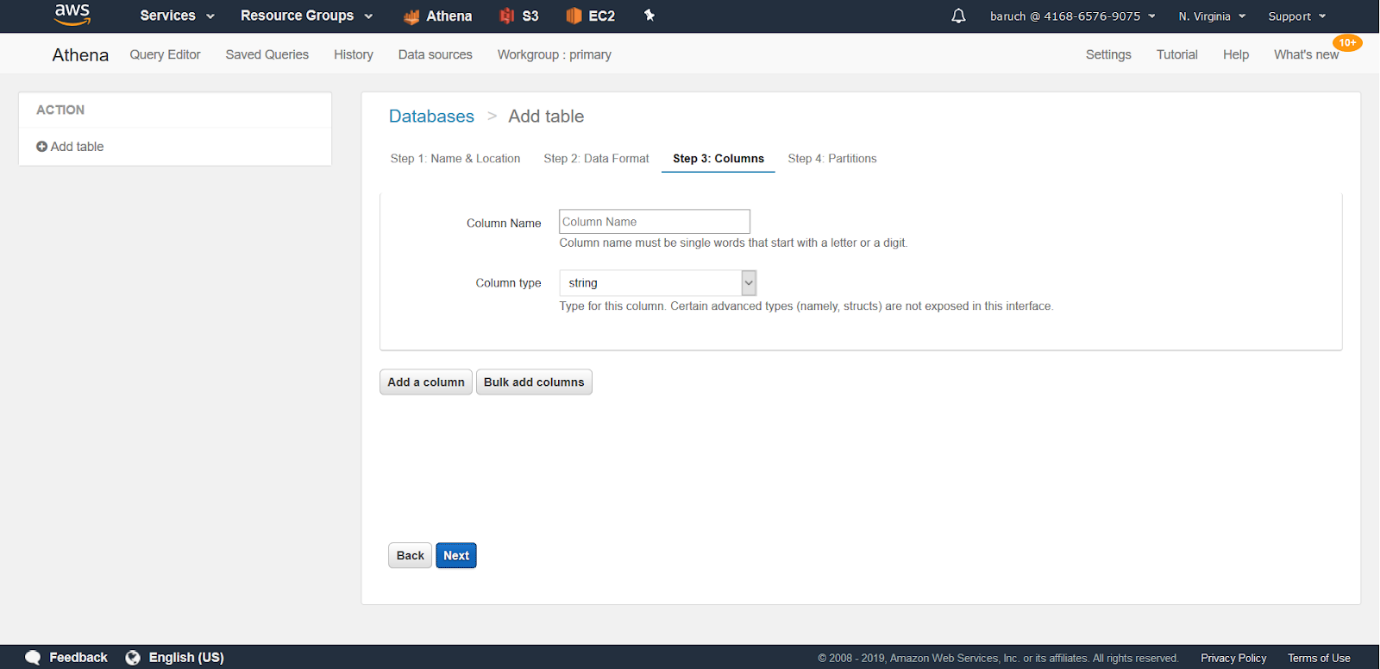
- Asigne un nombre a sus columnas y sus tipos (también puede agregar varias columnas en forma masiva) y haga clic en «Siguiente»
- El último paso es configurar las particiones:
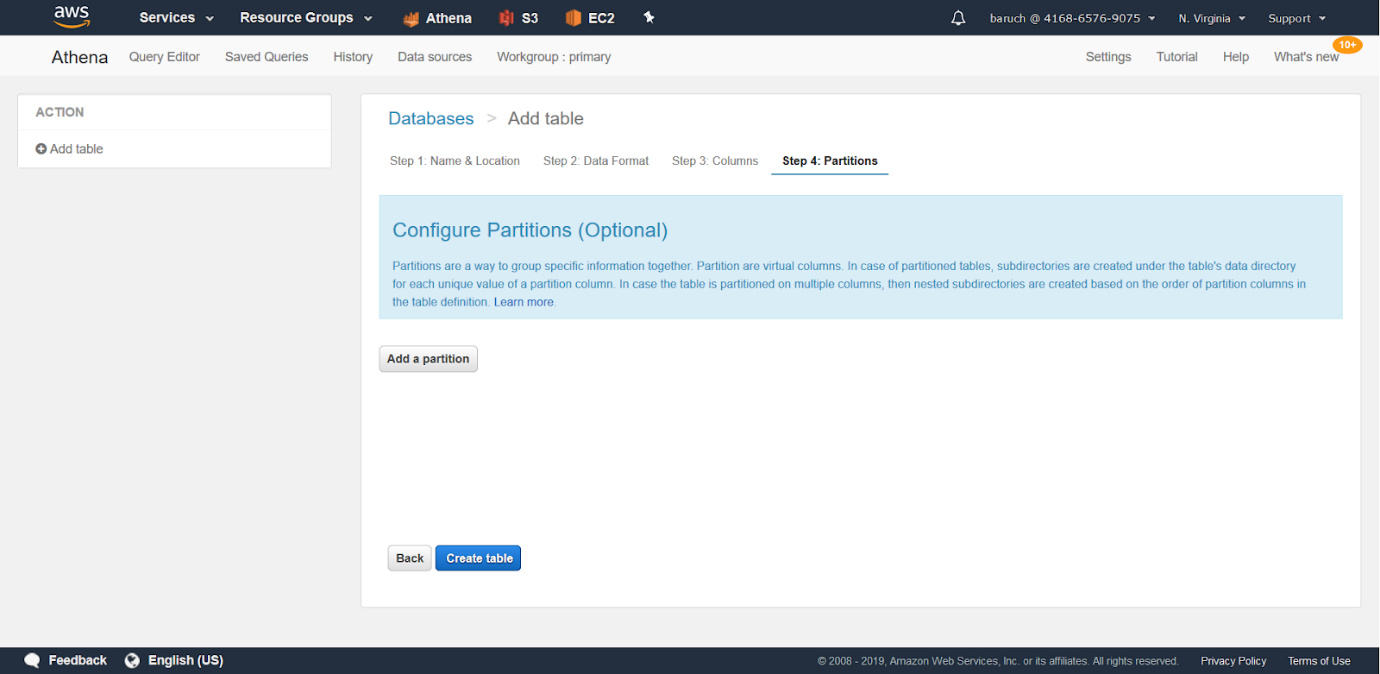
** Es importante tener en cuenta que, si tiene una columna que funciona como la clave de partición, no debe incluirla en las columnas, sino solo en la sección de partición.
- Haga clic en «Crear tabla», y su consulta SQL se completará.
Ahora, debería poder ver su tabla en el panel izquierdo y puede consultarla.
Otra forma de lograr esto es desde la pantalla que se ve a continuación:
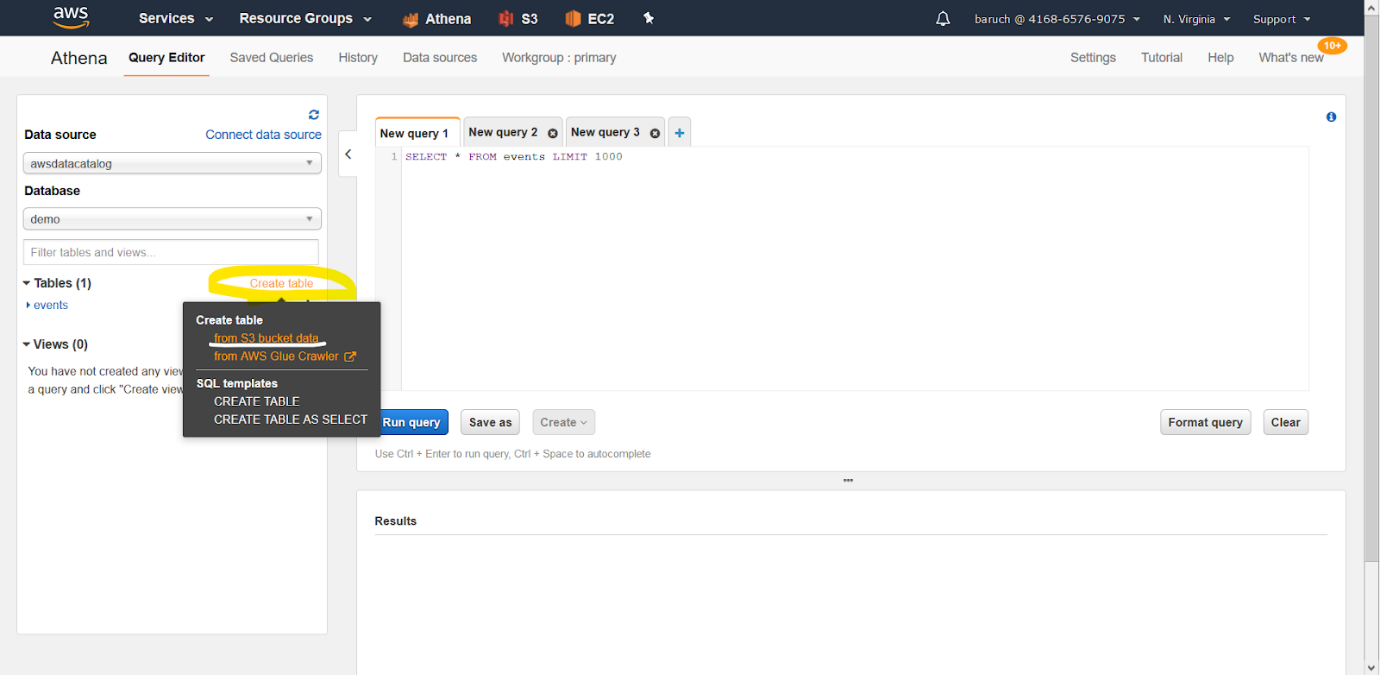
** Es importante saber que Athena en realidad no está creando tablas.
Lo que está haciendo es crear esquemas a partir de tablas, lo que nos permite diseñar consultas utilizando las tablas, a pesar de que los datos se encuentran en archivos no relacionados.
** preste atención para no poner archivos en su carpeta de origen, si no corresponden al esquema que acaba de definir.
Trate esta carpeta como un lugar donde inserte solo archivos que contengan filas u objetos con el mismo esquema.