
Diseño y desarrollo de aplicaciones en contenedor con Docker y Microsoft Azure Parte 2
Estado y datos en aplicaciones de Docker
En la mayoría de los casos, un contenedor se puede considerar como una instancia de un proceso. Un proceso no mantiene un estado persistente. Si bien un contenedor puede escribir en su almacenamiento local, suponer que una instancia permanecerá indefinidamente es como suponer que una sola ubicación en memoria será duradera. Debe suponerse que las imágenes del contenedor, como los procesos, tienen varias instancias y que finalmente desaparecerán; si se administran con un orquestador de contenedores, se debe suponer que podrían desplazarse de un nodo o máquina virtual a otro.
Las soluciones siguientes se usan para administrar datos persistentes en aplicaciones de Docker:
Desde el host de Docker, como volúmenes de Docker:
- Los volúmenes se almacenan en un área del sistema de archivos de host administrado por Docker.
- Los montajes de enlace pueden asignarse a cualquier carpeta del sistema de archivos de host, por lo que el acceso no se puede controlar desde el proceso de Docker y puede suponer un riesgo de seguridad ya que un contenedor podría acceder a carpetas del sistema operativo confidenciales.
- Los montajes tmpfs son como carpetas virtuales que solo existen en la memoria del host y nunca se escriben en el sistema de archivos.
Desde el almacenamiento remoto:
- Azure Storage proporciona almacenamiento con distribución geográfica y representa una buena solución de persistencia a largo plazo para los contenedores.
- Bases de datos relacionales remotas como Azure SQL Database, bases de datos NoSQL como Azure Cosmos DB o servicios de caché como Redis.
Desde el contenedor de Docker:
- Docker ofrece una característica denominada el sistema de archivos de superposición. Esta característica implementa una tarea de copia en escritura que almacena información actualizada en el sistema de archivos raíz del contenedor. Esa información «se coloca encima» de la imagen original en la que se basa el contenedor. Si se elimina el contenedor del sistema, estos cambios se pierden. Por tanto, si bien es posible guardar el estado de un contenedor dentro de su almacenamiento local, diseñar un sistema sobre esta base entraría en conflicto con la idea del diseño del contenedor, que de manera predeterminada es sin estado.
- Sin lugar a duda, los volúmenes de Docker son ahora la mejor manera de controlar datos locales en Docker. Si necesita obtener más información sobre el almacenamiento en contenedores, consulte Docker storage drivers (Controladores de almacenamiento de Docker) y About images, containers, and storage drivers (Acerca de las imágenes, los contenedores y los controladores de almacenamiento).
En los siguientes puntos se ofrece más información sobre estas opciones.
Los volúmenes son directorios asignados desde el sistema operativo del host a directorios en contenedores. Cuando el código en el contenedor tiene acceso al directorio, ese acceso es realmente a un directorio en el sistema operativo del host. Este directorio no está asociado a la duración del contenedor y Docker lo administra y aísla de la funcionalidad básica de la máquina host. Por tanto, los volúmenes de datos están diseñados para conservar los datos independientemente de la vida del contenedor. Si elimina un contenedor o una imagen del host de Docker, los datos que se conservan en el volumen de datos no se eliminan.
Los volúmenes pueden tener nombre o ser anónimos (predeterminado). Los volúmenes con nombre son la evolución de los Contenedores de volúmenes de datos y facilitan el uso compartido de datos entre contenedores. Los volúmenes también admiten controladores de volumen, que le permiten almacenar datos en hosts remotos, entre otras opciones.
Los montajes de enlace han estado disponibles durante mucho tiempo y permiten la asignación de cualquier carpeta a un punto de montaje en un contenedor. Los montajes de enlace tienen más limitaciones que los volúmenes y algunos problemas de seguridad importantes, por lo que los volúmenes son la opción recomendada.
Los montajes tmpfs son carpetas virtuales que solo existen en la memoria del host y nunca se escriben en el sistema de archivos. Son rápidos y seguros, pero usan memoria y solo están diseñados para datos no persistentes.
Tal como se muestra en la imagen 4-5, los volúmenes de Docker normales pueden almacenarse fuera de los propios contenedores, pero dentro de los límites físicos del servidor de host o de la máquina virtual. Sin embargo, los contenedores de Docker no pueden tener acceso a un volumen desde un servidor de host o máquina virtual a otro. En otras palabras, con estos volúmenes, no es posible administrar los datos que se comparten entre contenedores que se ejecutan en otros hosts de Docker, aunque se podría lograr con un controlador de volumen que sea compatible con los hosts remotos.
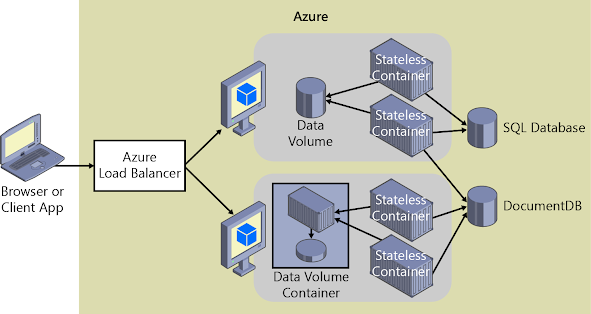
Imagen 4-5. Volúmenes y orígenes de datos externos para aplicaciones basadas en contenedor
Además, cuando un orquestador administra los contenedores de Docker, estos podrían «moverse» entre hosts, según las optimizaciones que el clúster realice. Por tanto, no se recomienda usar volúmenes de datos para los datos empresariales. Pero son un buen mecanismo para trabajar con archivos de seguimiento, archivos temporales o similares que no afectarán a la coherencia de los datos empresariales.
Las herramientas de orígenes de datos remotos y caché como Azure SQL Database, Azure Cosmos DB o una caché remota como Redis pueden usarse en aplicaciones en contenedores del mismo modo que se usan al desarrollar sin contenedores. Se trata de una manera comprobada para almacenar datos de aplicaciones empresariales.
Azure Storage. Normalmente, los datos empresariales deben colocarse en recursos o bases de datos externos, como Azure Storage. Azure Storage ofrece los siguientes servicios en la nube:
- Blob Storage almacena datos de objetos no estructurados. Un blob puede ser cualquier tipo de texto o datos binarios, como documentos o archivos multimedia (archivos de imagen, audio y vídeo). El almacenamiento de blobs a veces se conoce también como almacenamiento de objetos.
- File Storage ofrece almacenamiento compartido para aplicaciones heredadas que usan el protocolo SMB estándar. Las máquinas virtuales de Azure y los servicios en la nube pueden compartir datos de archivos en los componentes de la aplicación a través de recursos compartidos montados. Las aplicaciones locales pueden acceder a datos de archivos en un recurso compartido a través de la API REST de File Service.
- El almacenamiento de tablas almacena conjuntos de datos estructurados. El almacenamiento de tabla es un almacén de datos del atributo de clave NoSQL, lo que permite desarrollar y acceder rápidamente a grandes cantidades de datos.
Bases de datos relacionales y bases de datos NoSQL. Hay muchas opciones para bases de datos externas, desde bases de datos relacionales como SQL Server, PostgreSQL u Oracle hasta bases de datos NoSQL como Azure Cosmos DB, MongoDB, etc. Estas bases de datos no se van a explicar en esta guía porque pertenecen a un tema diferente.
Aplicaciones orientadas a servicios
Arquitectura orientada a servicios (SOA) era un término muy utilizado que significaba muchas cosas diferentes para diferentes personas. Pero, como denominador común, SOA significa que la arquitectura de una aplicación se estructura descomponiéndola en varios servicios (normalmente como servicios HTTP) que se pueden clasificar en tipos diferentes como subsistemas o, en otros casos, como niveles.
Esos servicios se pueden implementar ahora como contenedores de Docker, con lo que se resuelven los problemas de implementación, puesto que todas las dependencias se incluyen en la imagen de contenedor. De todos modos, cuando necesite escalar arquitecturas orientadas a servicios, puede que se encuentre con problemas si realiza una implementación en función de instancias únicas. Este problema puede controlarse con software de agrupación en clústeres de Docker o un orquestador. Los orquestadores se van a examinar más detalladamente en la sección siguiente, cuando se analicen los enfoques de microservicios.
Los contenedores de Docker son útiles (pero no obligatorios) para las arquitecturas orientadas a servicios tradicionales y las arquitecturas de microservicios más avanzadas.
En definitiva, las soluciones de agrupación en clústeres de contenedores resultan útiles tanto para una arquitectura tradicional de SOA como para una arquitectura de microservicios más avanzada en la que cada microservicio posee su modelo de datos. Y, gracias a varias bases de datos, también puede escalar horizontalmente el nivel de datos en lugar de trabajar con bases de datos monolíticas compartidas por los servicios SOA. No obstante, la discusión sobre la división de los datos se centra exclusivamente en la arquitectura y el diseño.
Orquestación de microservicios y aplicaciones de varios contenedores para una alta escalabilidad y disponibilidad
La utilización de orquestadores para aplicaciones listas para producción es fundamental si la aplicación se basa en microservicios o está dividida entre varios contenedores. Como se mencionó anteriormente, en un enfoque basado en microservicios, cada microservicio posee su modelo y sus datos para que sea autónomo desde un punto de vista del desarrollo y la implementación. Pero incluso si tiene una aplicación más tradicional que se compone de varios servicios (por ejemplo, SOA), también tendrá varios contenedores o servicios que conforman una sola aplicación de negocio que deban implementarse como un sistema distribuido. Estos tipos de sistemas son difíciles de administrar y escalar horizontalmente; por lo tanto, un orquestador es indispensable si se quiere tener una aplicación de varios contenedores, escalable y lista para la producción.
La imagen4-6 ilustra la implementación en un clúster de una aplicación formada por varios microservicios (contenedores).
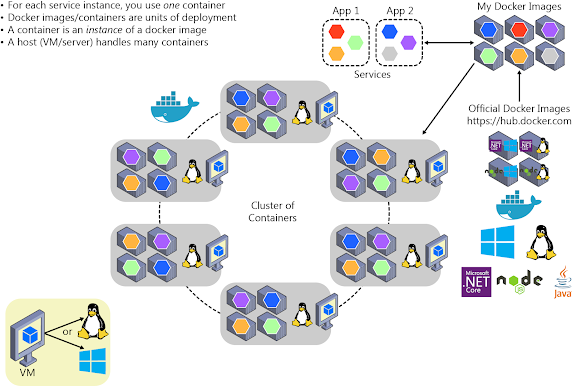
Imagen 4-6. Un clúster de contenedores
Parece un enfoque lógico. Pero ¿cómo se está administrando el equilibrio de carga, el enrutamiento y la orquestación de estas aplicaciones compuestas?
La CLI de Docker satisface las necesidades de administración de un contenedor en un host, pero se queda corta a la hora de administrar varios contenedores implementados en varios hosts para aplicaciones distribuidas más complejas. En la mayoría de los casos, se necesita una plataforma de administración que automáticamente inicie los contenedores, escale horizontalmente los contenedores con varias instancias por imagen, los suspenda o los cierre cuando sea necesario y, a ser posible, también controle su acceso a recursos como la red y el almacenamiento de datos.
Para ir más allá de la administración de contenedores individuales o aplicaciones compuestas simples y pasar a aplicaciones empresariales más grandes con microservicios, debe cambiar a orquestación y plataformas de agrupación en clústeres.
Desde el punto de vista de la arquitectura y el desarrollo, si está compilando grandes aplicaciones empresariales basadas en microservicios, es importante familiarizarse con las siguientes plataformas y productos que admiten escenarios avanzados:
- Clústeres y orquestadores. Cuando se necesita escalar horizontalmente las aplicaciones a varios hosts de Docker, como con una aplicación grande basada en microservicios, es fundamental poder administrar todos los hosts como un solo clúster mediante la abstracción de la complejidad de la plataforma subyacente. Eso es lo que proporcionan los clústeres de contenedor y los orquestadores. Azure Service Fabric y Kubernetes son ejemplos de orquestadores. Kubernetes está disponible en Azure a través de Azure Kubernetes Service.
- Programadores. Programar significa tener la capacidad de que un administrador inicie los contenedores de un clúster, por lo que los programadores también proporcionan una interfaz de usuario para hacerlo. Un programador de clúster tiene varias responsabilidades: usar eficazmente los recursos del clúster, establecer las restricciones definidas por el usuario, equilibrar eficazmente la carga de los contenedores entre los distintos nodos o hosts, ser resistente a los errores y proporcionar un alto grado de disponibilidad.
Los conceptos de un clúster y un programador están estrechamente relacionados, por lo que los productos proporcionados por diferentes proveedores suelen ofrecer ambos conjuntos de funciones. En la sección siguiente se muestran las plataformas y las opciones de software más importantes disponibles para clústeres y programadores. Estos orquestadores generalmente se ofrecen en nubes públicas como Azure.
Plataformas de software para agrupación en clústeres de contenedores, orquestación y programación
- Kubernetes es un producto de código abierto cuya funcionalidad abarca desde la infraestructura de clúster y la programación de contenedores a las capacidades de orquestación. Permite automatizar la implementación, la escala y las operaciones de contenedores de aplicaciones en varios clústeres de hosts.
- Kubernetes proporciona una infraestructura centrada en el contenedor que agrupa los contenedores de la aplicación en unidades lógicas para facilitar la administración y detección.
- Kubernetes está más desarrollado en Linux que en Windows.
- Azure Kubernetes Service (AKS) es un servicio de orquestación de contenedores de Kubernetes administrado en Azure que simplifica la administración, implementación y operaciones del clúster de Kubernetes.
- Azure Service Fabric es una plataforma de microservicios de Microsoft para crear aplicaciones. Es un orquestador de servicios y crea clústeres de máquinas. Service Fabric puede implementar servicios como contenedores o procesos estándar. Puede incluso combinar servicios en procesos con servicios en contenedores dentro de la misma aplicación y el mismo clúster.
- Los clústeres de Service Fabric pueden implementarse en Azure, de forma local o en cualquier nube. Con todo, la implementación se simplifica en Azure con un enfoque administrado.
- Service Fabric proporciona modelos de programación de Service Fabric prescriptivos adicionales y opcionales como servicios con estado y Reliable Actors.
- Service Fabric está más desarrollado en Windows (con años de evolución en Windows) que en Linux.
- Tanto los contenedores de Linux como los de Windows son compatibles con Service Fabric desde 2017.
- Azure Service Fabric Mesh ofrece el mismo nivel de fiabilidad, rendimiento crítico y escala que Service Fabric, pero también proporciona una plataforma totalmente administrada y sin servidor. No es necesario administrar un clúster, las máquinas virtuales, el almacenamiento o la configuración de red. Puede centrarse en el desarrollo de la aplicación.
- Service Fabric Mesh admite contenedores de Windows y Linux, lo que permite desarrollar con cualquier lenguaje de programación y marco de trabajo que elija.
Uso de orquestadores basados en contenedor en Azure
Existen varios proveedores de nube que ofrecen compatibilidad con contenedores de Docker más compatibilidad con la orquestación y los clústeres de Docker, como Azure, Amazon EC2 Container Service y Google Container Engine. Azure proporciona compatibilidad con el orquestador y el clúster de Docker a través de Azure Kubernetes Service (AKS), Azure Service Fabric y Azure Service Fabric Mesh.
Uso de Azure Kubernetes Service
Un clúster de Kubernetes agrupa varios hosts de Docker y los expone como un único host virtual de Docker, lo que permite implementar varios contenedores en el clúster y escalar horizontalmente con cualquier número de instancias de contenedor. El clúster controlará toda la mecánica de administración compleja, como la escalabilidad, el estado, etc.
AKS proporciona una manera de simplificar la creación, la configuración y la administración de un clúster de máquinas virtuales en Azure que están preconfiguradas para ejecutar aplicaciones en contenedores. Al utilizar una configuración optimizada de herramientas de orquestación y programación de código abierto populares, AKS le permite usar sus habilidades existentes o aprovechar un gran corpus creciente de conocimientos de la comunidad para implementar y administrar aplicaciones basadas en contenedor en Microsoft Azure.
Azure Kubernetes Service optimiza la configuración de tecnologías y herramientas populares de código abierto de agrupación en clústeres de Docker específicamente para Azure. Se trata de una solución abierta que ofrece la portabilidad de los contenedores y la configuración de la aplicación. Seleccione el tamaño, el número de hosts y las herramientas de orquestador, y AKS se encarga de todo lo demás.
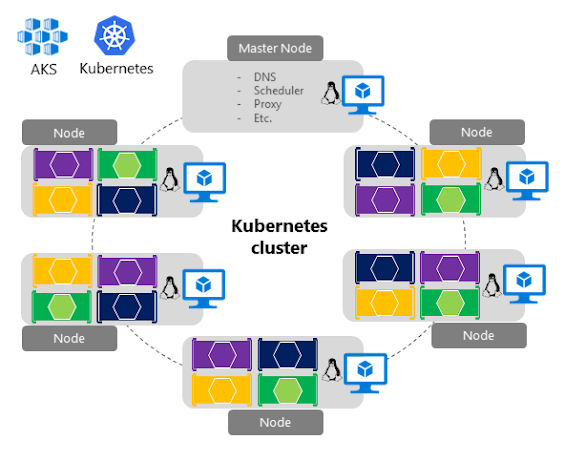
Imagen 4-7. Topología y estructura simplificada del clúster de Kubernetes
En la figura 4-7 se muestra la estructura de un clúster de Kubernetes, donde un nodo maestro (VM) controla la mayor parte de la coordinación del clúster y puede implementar contenedores en el resto de los nodos que se administran como un único grupo desde el punto de vista de la aplicación. Esto le permite escalar a miles o incluso a decenas de miles de contenedores.
Entorno de desarrollo para Kubernetes
En el entorno de desarrollo, Docker anunció en julio de 2018 que Kubernetes también puede ejecutarse en un único equipo de desarrollo (Windows 10 o macOS). Basta con instalar Docker Desktop. Puede implementar posteriormente en la nube (AKS) para obtener más pruebas de integración, como se muestra en la imagen 4-8.
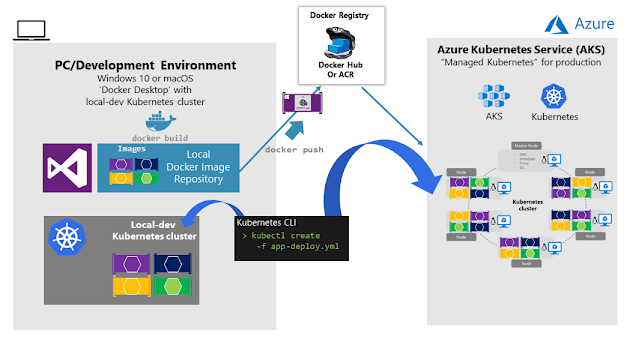
Imagen 4-8. Ejecución de Kubernetes en el equipo de desarrollo y la nube
Introducción a Azure Kubernetes Service (AKS)
Para empezar a usar AKS, implemente un clúster de AKS desde Azure Portal o mediante la CLI. Para obtener más información sobre la implementación de un clúster de Kubernetes en Azure, vea Inicio rápido: Implementación de un clúster de Azure Kubernetes Service (AKS).
No hay cuotas para el software instalado de forma predeterminada como parte de AKS. Todas las opciones predeterminadas se implementan con el software de código abierto. AKS está disponible en varias máquinas virtuales en Azure. Se cobra únicamente por las instancias de proceso que se elijan, así como por los otros recursos subyacentes de la infraestructura que se utilicen como, por ejemplo, la red y el almacenamiento. No hay ningún cargo incremental para AKS.
Para obtener más información sobre la implementación en Kubernetes en función de kubectl y archivos .yaml originales, vea Implementación en Azure Kubernetes Service (AKS).
Implementación con gráficos de Helm en clústeres de Kubernetes
Al implementar una aplicación en un clúster de Kubernetes, puede usar la herramienta de CLI kubectl.exe original mediante archivos de implementación basados en el formato nativo (archivos .yaml), como ya se mencionó en la sección anterior. Pero, para aplicaciones de Kubernetes más complejas, como al implementar aplicaciones complejas basadas en microservicios, se recomienda usar Helm.
Los gráficos de Helm le ayudan a definir, establecer la versión, instalar, compartir, actualizar o revertir incluso la aplicación más compleja de Kubernetes.
Adicionalmente, el uso de Helm se recomienda porque otros entornos de Kubernetes en Azure, como Azure Dev Spaces, también se basan en los gráficos de Helm.
La Cloud Native Computing Foundation (CNCF) mantiene Helm en colaboración con Microsoft, Google, Bitnami y la comunidad de colaboradores de Helm.
Para obtener más información sobre la implementación en gráficos de Helm y Kubernetes, vea la sección Instalación de eShopOnContainers mediante Helm.
Uso de Azure Dev Spaces para el ciclo de vida de la aplicación de Kubernetes
Azure Dev Spaces proporciona una experiencia de desarrollo de Kubernetes rápida e iterativa para los equipos. Con una configuración de máquina de desarrollo mínima, puede ejecutar y depurar contenedores de forma iterativa directamente en Azure Kubernetes Service (AKS). Puede desarrollar en Windows, Mac o Linux mediante herramientas familiares como Visual Studio, Visual Studio Code o la línea de comandos.
Como ya se ha mencionado, Azure Dev Spaces usa gráficos de Helm al implementar aplicaciones basadas en contenedores.
Azure Dev Spaces ayuda a los equipos de desarrollo a ser más productivos en Kubernetes porque permite iterar con rapidez y depurar código directamente en un clúster de Kubernetes global en Azure simplemente mediante el uso de Visual Studio 2017 o Visual Studio Code. Ese clúster de Kubernetes en Azure es un clúster de Kubernetes administrado compartido, por lo que su equipo puede colaborar. Puede desarrollar código de forma aislada, después implementarlo en el clúster global y realizar pruebas de un extremo a otro con otros componentes sin tener que replicar ni simular dependencias.
Como se muestra en la imagen 4-9, la característica distintiva de Azure Dev Spaces es la capacidad de crear «espacios» que se pueden ejecutar integrados con el resto de la implementación global en el clúster:
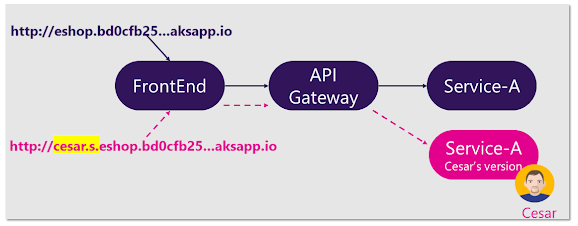
Imagen 4-9. Uso de varios espacios en Azure Dev Spaces
Azure Dev Spaces puede mezclar y combinar de forma transparente los microservicios de producción con la instancia de contenedor de desarrollo para facilitar las pruebas de nuevas versiones. Básicamente, puede configurar un espacio de desarrollo compartido en Azure. Así, cada programador se puede centrar exclusivamente en su parte de la aplicación y desarrollar de forma iterativa código previo a la confirmación en un espacio de desarrollo que ya contenga todos los demás servicios y recursos en la nube de los que sus escenarios dependen. Las dependencias siempre estarán actualizadas y los desarrolladores trabajarán de una manera que se asemeja bastante a un entorno de producción.
En Azure Dev Spaces existe el concepto de espacio, que permite trabajar de manera aislada y sin riesgo de romper el código de los miembros del equipo. Esta característica se basa en prefijos de dirección URL. Si usa un prefijo de espacio de desarrollo en la dirección URL para la solicitud de un contenedor, Azure Dev Spaces ejecutará una versión especial del contenedor que se implementa para ese espacio, si existe. En caso contrario, se ejecutará la versión global o consolidada.
Para obtener un ejemplo concreto, vea la página wiki de eShopOnContainers en Azure Dev Spaces.
Para obtener más información, vea Desarrollo en equipo con Azure Dev Spaces.
Recursos adicionales
- Guía de inicio rápido: Implementación de un clúster de Azure Kubernetes Service (AKS)
https://docs.microsoft.com/azure/aks/kubernetes-walkthrough-portal
- Azure Dev Spaces
https://docs.microsoft.com/azure/dev-spaces/azure-dev-spaces
- Kubernetes. Sitio oficial.
https://kubernetes.io/
Uso de Azure Service Fabric
Azure Service Fabric surgió de la transición que Microsoft realizó al dejar de ofrecer productos empaquetados, que normalmente tenían un estilo monolítico, para ofrecer servicios. La experiencia de crear y usar servicios de gran tamaño a escala, como Azure SQL Database, Azure Cosmos DB, Azure Service Bus o Backend de Cortana, definió el formato de Service Fabric. La plataforma evolucionó con el tiempo, a medida que la adoptaron cada vez más servicios. Cabe destacar que Service Fabric tuvo que ejecutarse no solo en Azure sino también en implementaciones independientes de Windows Server.
El objetivo de Service Fabric es solucionar los arduos problemas de compilar y ejecutar un servicio y usar recursos de infraestructura de forma eficaz, de manera que los equipos puedan resolver problemas empresariales con un enfoque de microservicios.
Service Fabric proporciona dos áreas generales para ayudarlo a crear aplicaciones que usan un enfoque de microservicios:
- Una plataforma que proporciona servicios de sistema para implementar, escalar, actualizar, detectar y reiniciar servicios erróneos, detectar la ubicación del servicio, administrar el estado y supervisar el mantenimiento. Estos servicios de sistema efectivamente habilitan muchas de las características de microservicios descritas anteriormente.
- Programar API, o marcos, para ayudarlo a crear aplicaciones como microservicios: actores fiables y servicios de confianza. Puede elegir cualquier código para generar el microservicio, pero estas API facilitan el trabajo y se integran con la plataforma a un nivel más profundo. De este modo, puede obtener información de mantenimiento y diagnóstico o puede sacar partido de la administración de estado confiable.
Para crear su servicio puede usar cualquier tecnología ya que Service Fabric no interviene en el proceso. Sin embargo, proporciona API de programación integradas que facilitan la creación de microservicios.
Como se muestra en la imagen 4-10, puede crear y ejecutar microservicios en Service Fabric como procesos simples o como contenedores de Docker. También es posible mezclar microservicios basados en contenedores con microservicios basados en procesos en el mismo clúster de Service Fabric.
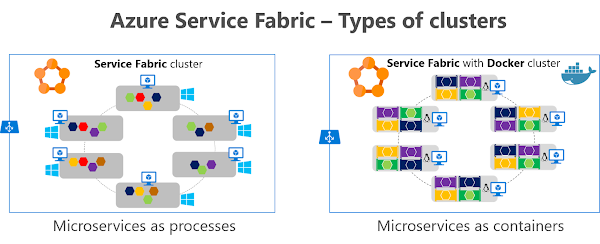
Imagen 4-10. Implementar microservicios como procesos o como contenedores en Azure Service Fabric
En la primera imagen, verá microservicios como procesos, donde cada nodo ejecuta un proceso para cada microservicio. En la segunda imagen, verá microservicios como contenedores, donde cada nodo ejecuta Docker con varios contenedores, un contenedor por microservicio. Los clústeres de Service Fabric basados en hosts de Linux y Windows pueden ejecutar contenedores de Docker Linux y Windows, respectivamente.
Para más información actualizada sobre la compatibilidad con contenedores en Azure Service Fabric, vea Service Fabric y contenedores.
Service Fabric es un buen ejemplo de una plataforma en la que puede definir una arquitectura lógica diferente (microservicios empresariales o contextos limitados) de la implementación física. Por ejemplo, si implementa en Azure Service Fabric los servicios de confianza con estado, que se describen más adelante en la sección Microservicios sin estado frente a microservicios con estado, puede tener un concepto de microservicio empresarial con varios servicios físicos.
Como se muestra en la imagen 4-10, y bajo una perspectiva de microservicio lógico o empresarial, al implementar un servicio de confianza con estado de Service Fabric, normalmente deberá implementar dos niveles de servicios. El primero es el servicio de confianza con estado back-end, que administra varias particiones (cada partición es un servicio con estado). El segundo es el servicio front-end, o servicio de puerta de enlace, que se encarga del enrutamiento y de la agregación de datos en varias particiones o instancias de servicio con estado. Este servicio de puerta de enlace también controla la comunicación del lado cliente con los bucles de reintento que acceden al servicio back-end. Se denomina servicio de puerta de enlace si implementa el servicio personalizado, pero alternativamente también puede usar el proxy inverso estándar de Service Fabric.
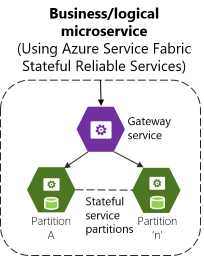
Imagen 4-11. Microservicio de negocio con varias instancias de servicio con estado y un front-end con puerta de enlace personalizado
En cualquier caso, al usar servicios de confianza con estado de Service Fabric, también dispone de un microservicio lógico o empresarial (contexto limitado) que se compone de varios servicios físicos. Cada uno de ellos, el servicio de puerta de enlace y el servicio de partición podrían implementarse como servicios ASP.NET Web API, como se muestra en la imagen 4-11. Service Fabric está recomendado para admitir varios servicios de confianza con estado en contenedores.
En Service Fabric, puede agrupar e implementar grupos de servicios como una aplicación de Service Fabric, que es la unidad de empaquetado e implementación para el orquestador o clúster. Por tanto, la aplicación de Service Fabric también podría asignarse a este límite de microservicio o contexto limitado lógico y empresarial autónomo, por lo que podría implementar estos servicios de forma autónoma.
Service Fabric y contenedores
Con respecto a los contenedores de Service Fabric, también puede implementar servicios en las imágenes de contenedor dentro de un clúster de Service Fabric. Como se muestra en la figura 4-12, la mayoría de las veces solo habrá un contenedor por cada servicio.
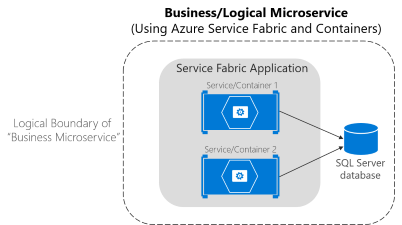
Imagen 4-12. Microservicio empresarial con varios servicios (contenedores) en Service Fabric
Una aplicación de Service Fabric puede ejecutar varios contenedores que acceden a una base de datos externa y el conjunto completo sería el límite lógico de un microservicio empresarial. Pero los contenedores llamados «asociados» (dos contenedores que deben implementarse conjuntamente como parte de un servicio lógico) también son posibles en Service Fabric. Lo importante es que un microservicio empresarial sea el límite lógico alrededor de varios elementos cohesivos. En muchos casos, puede que sea un único servicio con un solo modelo de datos, pero en otros casos también es posible que tenga varios servicios físicos.
Tenga en cuenta que se pueden combinar servicios en procesos y servicios en contenedores en la misma aplicación de Service Fabric, como se muestra en la imagen 4-13.
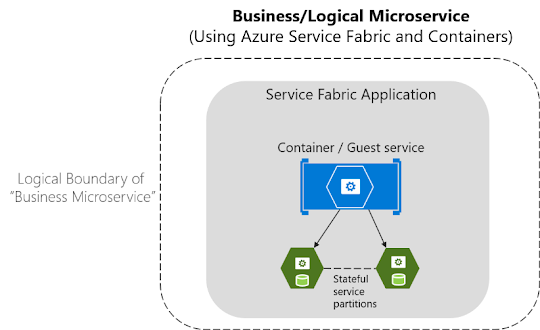
Imagen 4-13. Microservicio empresarial asignado a una aplicación de Service Fabric con contenedores y servicios con estado
Para más información sobre la compatibilidad de contenedor en Azure Service Fabric, vea Service Fabric y contenedores.
Microservicios sin estado frente a microservicios con estado
Como se ha mencionado anteriormente, cada microservicio (contexto limitado lógico) debe tener su modelo de dominio (datos y lógica). En el caso de los microservicios sin estado, las bases de datos serán externas y se usarán opciones relacionales, como SQL Server, u opciones de NoSQL, como MongoDB o Azure Cosmos DB.
Pero los propios servicios también pueden ser con estado en Service Fabric, lo que significa que los datos se encuentran en el microservicio. Estos datos pueden existir no solo en el mismo servidor, sino dentro del proceso del microservicio, en memoria, conservados en discos duros y replicados en otros nodos. En la imagen 4-14 se muestran los distintos enfoques.
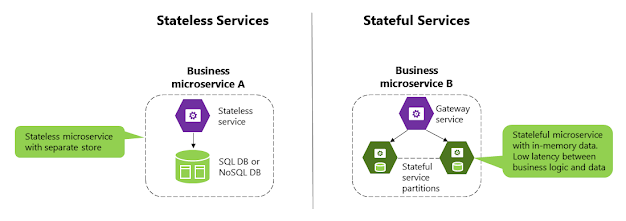
Imagen 4-14. Microservicios sin estado frente a microservicios con estado
En los servicios sin estado, el estado (persistencia, base de datos) se mantiene fuera del microservicio. En los servicios con estado, el estado se mantiene dentro del microservicio. Un enfoque sin estado es perfectamente válido y es más fácil de implementar que los microservicios con estado, ya que el enfoque es similar a los patrones tradicionales y conocidos. Pero los microservicios sin estado imponen latencia entre el proceso y los orígenes de datos. También implican más piezas móviles cuando se intenta mejorar el rendimiento con memoria caché y colas adicionales. El resultado es que puede acabar con arquitecturas complejas que tienen demasiados niveles.
Por el contrario, los microservicios con estado pueden destacar en escenarios avanzados, ya que no hay latencia entre los datos y la lógica del dominio. El procesamiento intenso de datos, los back-ends de juegos, las bases de datos como servicio y otros escenarios con baja latencia se benefician de los servicios con estado, que habilitan el estado local para un acceso más rápido.
Los servicios sin estado y los servicios con estado se complementan. Por ejemplo, como puede ver en el diagrama de la derecha en la imagen 4-14, un servicio con estado se puede dividir en varias particiones. Para acceder a esas particiones, es posible que deba contar con un servicio sin estado que actúe como un servicio de puerta de enlace que sepa cómo dirigirse a cada partición en función de las claves de partición.
Los servicios con estado tienen diversos inconvenientes. Imponen un alto nivel de complejidad en el escalado horizontal. Las funciones que normalmente se implementarían mediante sistemas de bases de datos externas se debe abordar en tareas como la replicación de datos a través de microservicios con estado y la creación de particiones de datos. Sin embargo, esta es una de las áreas en que un orquestador como Azure Service Fabric con sus servicios de confianza con estado puede ayudar al máximo, ya que simplifica el desarrollo y el ciclo de vida de los microservicios con estado mediante la API de Reliable Services y Reliable Actors.
Otros marcos de microservicio que permiten los servicios con estado, admiten el patrón de actor y mejoran la tolerancia a errores y la latencia entre la lógica y los datos de negocios son Microsoft Orleans, de Microsoft Research, y Akka.NET. Actualmente, ambos marcos están mejorando su compatibilidad con Docker.
Recuerde que los contenedores de Docker son sin estado. Si quiere implementar un servicio con estado, debe contar con uno de los marcos prescriptivos y de nivel superior adicionales que se han indicado anteriormente.
Uso de Azure Service Fabric Mesh
Azure Service Fabric Mesh es un servicio totalmente administrado que permite a los desarrolladores compilar e implementar aplicaciones críticas sin tener que administrar ninguna infraestructura. Utilice Service Fabric Mesh para compilar y ejecutar aplicaciones de microservicios seguras y distribuidas que se escalan a petición.
Como se muestra en la imagen 4-15, las aplicaciones hospedadas en Service Fabric Mesh se ejecutan y escalan sin preocuparse por la infraestructura de la que dependen.
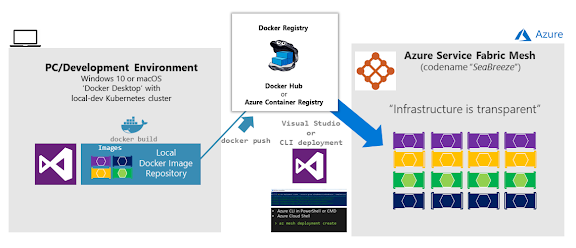
Imagen 4-15. Implementación de una aplicación de microservicios/contenedores en Service Fabric Mesh
En segundo plano, Service Fabric Mesh consta de clústeres de miles de máquinas. Todas las operaciones de clúster se ocultan a los desarrolladores. Basta con cargar los contenedores y especificar los recursos necesarios, los requisitos de disponibilidad y los límites de recursos. Service Fabric Mesh asigna automáticamente la infraestructura solicitada por la implementación de la aplicación y también controla los errores de infraestructura, asegurándose de que las aplicaciones tienen una alta disponibilidad. Solo necesita preocuparse del estado y de la capacidad de respuesta de la aplicación, nunca de la infraestructura.
Para obtener más información, vea la documentación de Service Fabric Mesh.
Elección de orquestadores en Azure
En la siguiente tabla se proporcionan instrucciones sobre qué orquestador se debe usar en función de las cargas de trabajo y el foco del sistema operativo.

Imagen 4-16. Selección del orquestador en instrucciones de Azure