
Aplicaciones con estado en Kubernetes con StatefulSets

Siempre que puedas desarrollar aplicaciones sin estado, que no dependan ni deban conocer al resto de réplicas, te va a permitir tener un desarrollo altamente escalable y ágil. Sin embargo esto no es siempre posible. Existen algunos tipos donde cada réplica no solo necesita de su propio almacenamiento, sino que su identidad sea estable en el tiempo. También es importante mantener un orden y ser conscientes del resto de integrantes/pods. En este artículo quiero contarte cómo desplegar aplicaciones con estado en Kubernetes, usando el recurso StatefulSet y un clúster de MongoDB como ejemplo.
StatefulSet
Para poder trabajar en Kubernetes con este tipo de aplicaciones necesitamos utilizar un recurso llamado StatefulSet. Estos se caracterízan, a diferencia de los Deployments, por proveer a nuestras aplicaciones de las siguientes capacidades:
- Almacenamiento persistente e independiente para cada uno de los pods.
- Identificador predecible y estable en el tiempo.
- Despliegue, escalado y actualizaciones de manera ordenada entre las réplicas.
Para verlo con un ejemplo, voy a desplegar un clúster de MongoDB, que seguro que te aclarará cada uno de los puntos. Debes tener en cuenta que para poder trabajar con StatefulSets necesitarás antes tener disponibles los siguientes recursos:
- Un servicio del tipo headless.
- Una StorageClass que definirá el volumen persistente, que se creará por cada nodo del clúster de Mongo DB.
Crear un servicio headless
Antes de crear el recurso StatefulSet necesitas un servicio del tipo headless. Este se encargará de gestionar las IPs de los pods creados por el recurso, a través del selector que se establezca, y será capaz de asociar cada pod con la IP correspondiente.
apiVersion: v1
kind: Service
metadata:
name: mongodb-svc
labels:
app: db
name: mongodb
spec:
clusterIP: None
selector:
app: db
name: mongodb
ports:
– port: 27017
targetPort: 27017
Como puedes ver, para que un servicio sea headless simplemente hay que poner la propiedad clusterIP a None.
Al crearlo, comprobarás que el servicio no tiene asociada ninguna IP interna, ya que no es necesario que balancee entre los pods:
Giselas-iMac:statefulset gis$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 23m
mongodb-svc ClusterIP None <none> 27017/TCP 5s
Por ahora tampoco tiene ningún endpoint asociado, como era de esperar:
Giselas-iMac:statefulset gis$ kubectl describe svc mongodb-svc
Name: mongodb-svc
Namespace: default
Labels: app=db
name=mongodb
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{«apiVersion»:»v1″,»kind»:»Service»,»metadata»:{«annotations»:{},»labels»:{«app»:»db»,»name»:»mongodb»},»name»:»mongodb-svc»,»namespace»:»…
Selector: app=db,name=mongodb
Type: ClusterIP
IP: None
Port: <unset> 27017/TCP
TargetPort: 27017/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
Crear un StorageClass
Si estás trabajando con Azure Kubernetes Service como yo, ya tienes estas storage classes creadas por defecto:
Giselas-iMac:statefulset gis$ kubectl get storageclass
NAME PROVISIONER AGE
azurefile kubernetes.io/azure-file 4d17h
azurefile-premium kubernetes.io/azure-file 4d17h
default (default) kubernetes.io/azure-disk 4d17h
managed-premium kubernetes.io/azure-disk 4d17h
Sin embargo, para hacer el ejemplo de principio a fin, voy a crear un StorageClass específico para este escenario:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: storage-mongo
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Retain
parameters:
kind: Managed
storageaccounttype: StandardSSD_LRS
En este caso, he elegido el tipo Azure Disk, ya que los volúmenes que se generen solo serán asociados a un único pod, y como tipo he utilizado el Standard SSD con redundancia local.
Crear el recurso StatefulSet
Ahora que ya tienes el servicio headless y una storage class, ya puedes definir el recurso Statefulset con la configuración de MongoDB en formato clúster o replica set:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongo
spec:
selector:
matchLabels:
app: db
name: mongodb
serviceName: mongodb-svc #the name of the headless service
replicas: 3
template:
metadata:
labels:
app: db
name: mongodb
spec:
terminationGracePeriodSeconds: 10 #This is important for databases
containers:
– name: mongo
image: mongo:3.6
– mongod
args:
– –bind_ip=0.0.0.0
– –replSet=rs0 #The name of the replica set that the mongod is part of. All hosts in the replica set must have the same set name.
– –dbpath=/data/db
livenessProbe:
exec:
command:
– mongo
– –eval
– «db.adminCommand(‘ping’)»
ports:
– containerPort: 27017
volumeMounts:
– name: mongo-storage
mountPath: /data/db
volumeClaimTemplates:
– metadata:
name: mongo-storage
spec:
storageClassName: storage-mongo
accessModes: [«ReadWriteOnce»]
resources:
requests:
storage: 100Gi
Como puedes ver, la definición del StatefulSet necesita el nombre del servicio headless que creaste (serviceName), el número de replicas, una plantilla que defina los pods y otra plantilla para los volúmenes que se deben generar por cada una de las réplicas, en la cual se indica la storage class creada anteriormente. En el caso de MongoDB, hay que configurarlo en modo replica set, y es por ello que necesitas el apartado command y args (más información aquí).
Crea este recurso y lista los StatefulSets dentro de tu clúster.
Giselas-iMac:statefulset gis$ kubectl apply -f statefulset.yaml
statefulset.apps/mongo created
Giselas-iMac:statefulset gis$ kubectl get statefulset
NAME READY AGE
mongo 0/3 8s
Como ves, está a la espera de las tres réplicas. También puedes consultar los pods para ver cómo va el progreso:
Giselas-iMac:statefulset gis$ kubectl get po
NAME READY STATUS RESTARTS AGE
mongo-0 1/1 Running 0 2m39s
mongo-1 0/1 Pending 0 8s
Lo primero que llama la atención, si lo comparamos con los Deployments, es que primer pod se ha creado con el nombre del StatetfulSet seguido de -0, y hasta que este no ha comenzado a ejecutarse el siguiente pod no ha aparecido en listado para su creación, y así hasta cumplir con el número de réplicas elegidas:
Giselas-iMac:statefulset gis$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mongo-0 1/1 Running 0 2m50s
mongo-1 1/1 Running 0 2m10s
mongo-2 1/1 Running 0 92s
Esta es una de las características que comenté al principio de este artículo: el despliegue se realiza de manera ordenada, no se utilizan nombres aleatorios sino que siguen un indice. Es por ello que el proceso será mucho más lento.
Lo siguiente que puedes comprobar es si, tal y como se definió en el StatefulSet, se han creado los volúmenes persistentes para cada uno de los pods con la storage class creada:
Giselas-iMac:statefulset gis$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-8bf21368-9650-47a0-bdaf-2380abb5d4e0 100Gi RWO Retain Bound default/mongo-storage-mongo-2 storage-mongo 9m39s
pvc-bc620a6f-7ab5-4678-b172-edb960422f19 100Gi RWO Retain Bound default/mongo-storage-mongo-1 storage-mongo 10m
pvc-e2119a57-bb46-4406-91ec-74f811ee832a 100Gi RWO Retain Bound default/mongo-storage-mongo-0 storage-mongo 22m
Por último, si vuelves a comprobar los endpoints asociados al servicio verás que ahora contendrá tres IPs consecutivas:
Giselas-iMac:statefulset gis$ kubectl describe endpoints mongodb-svc
Name: mongodb-svc
Namespace: default
Labels: app=db
name=mongodb
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2020-05-02T23:04:35Z
Subsets:
Addresses: 10.244.0.64,10.244.0.65,10.244.0.66
NotReadyAddresses: <none>
Ports:
Name Port Protocol
—- —- ——–
<unset> 27017 TCP
Events: <none>
Inicializar el replica set de MongoDB
Ahora ya tienes tus tres réplicas funcionando, pero todavía no están trabajando conjuntamente como un clúster. Para ello es necesario inicializar el mismo desde dentro de uno de los pods:
#Connect mongo-0
kubectl exec -it mongo-0 mongo
Una vez dentro debes lanzar rs.initiate con los FQDN de cada uno de los pods de la siguiente manera:
#Initiate the replicaset
rs.initiate({_id: «rs0», version: 1, members: [
{ _id: 0, host : «mongo-0.mongodb-svc.default.svc.cluster.local:27017» },
{ _id: 1, host : «mongo-1.mongodb-svc.default.svc.cluster.local:27017» },
{ _id: 2, host : «mongo-2.mongodb-svc.default.svc.cluster.local:27017» }
]});
Al hacer esto deberías de obtener un mensaje como el siguiente:
> rs.initiate({_id: «rs0», version: 1, members: [
… { _id: 0, host : «mongo-0.mongodb-svc.default.svc.cluster.local:27017» },
… { _id: 1, host : «mongo-1.mongodb-svc.default.svc.cluster.local:27017» },
… { _id: 2, host : «mongo-2.mongodb-svc.default.svc.cluster.local:27017» }
… ]});
{
«ok» : 1,
«operationTime» : Timestamp(1588460857, 1),
«$clusterTime» : {
«clusterTime» : Timestamp(1588460857, 1),
«signature» : {
«hash» : BinData(0,»AAAAAAAAAAAAAAAAAAAAAAAAAAA=»),
«keyId» : NumberLong(0)
}
}
}
rs0:SECONDARY>
Lo cual significa que ya tienes todos tus pods trabajando de manera conjunta. Para confirmar la configuración puedes lanzar por último este comando:
rs.conf()
Con él recuperarás todos los miembros de tu clúster y el host asociado a cada uno de ellos, el cual gracias al StatefulSet sabemos que no cambiará, incluso si algo le pasa a los pods.
Nota: Este proceso de inicialización se suele automatizar, sobre todo pensando en si queremos escalar de manera automática el clúster de MongoDB. Sin embargo, en este artículo quería que vieras cómo es el proceso manual y cómo se hace uso de las identidades estáticas de los pods.
Probar el clúster de MongoDB en Kubernetes
Ahora que ya tienes tu clúster funcionando con tres réplicas, las cuales se han ido creando de manera secuencial, tienen una identidad que sabemos que no va a cambiar, así como su propio almacenamiento, lo último que nos queda por comprobar es que funciona correctamente. Para ello voy a crear un despligue con Mongo Express:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo-express
labels:
app: web
name: mongo-express
spec:
replicas: 2
selector:
matchLabels:
app: web
name: mongo-express
template:
metadata:
labels:
app: web
name: mongo-express
spec:
containers:
– name: mongo-express
image: mongo-express
env:
– name: ME_CONFIG_MONGODB_SERVER
value: mongodb://mongo-0.mongodb-svc,mongo-1.mongodb-svc,mongo-2.mongodb-svc?replicaSet=ns0
ports:
– containerPort: 8081
—
apiVersion: v1
kind: Service
metadata:
name: mongo-express-svc
spec:
type: LoadBalancer
selector:
app: web
name: mongo-express
ports:
– protocol: TCP
port: 80
targetPort: 8081
Para indicar que tenemos un replica set, he modificado el valor de la variable ME_CONFIG_MONGODB_SERVER utilizando una cadena de conexión que especifica todos los miembros del clúster, una vez más haciendo uso de los identificadores que StatefulSet te proporciona, garantizándote de que estos no cambiarán. También he definido un servicio del tipo LoadBalancer para que puedas acceder a la web desde fuera de Kubernetes. Revisa la IP del servicio mongo-express para acceder al mismo.
Mongo Express en Kubernetes
Crea una base de datos y añade si quieres algún documento.
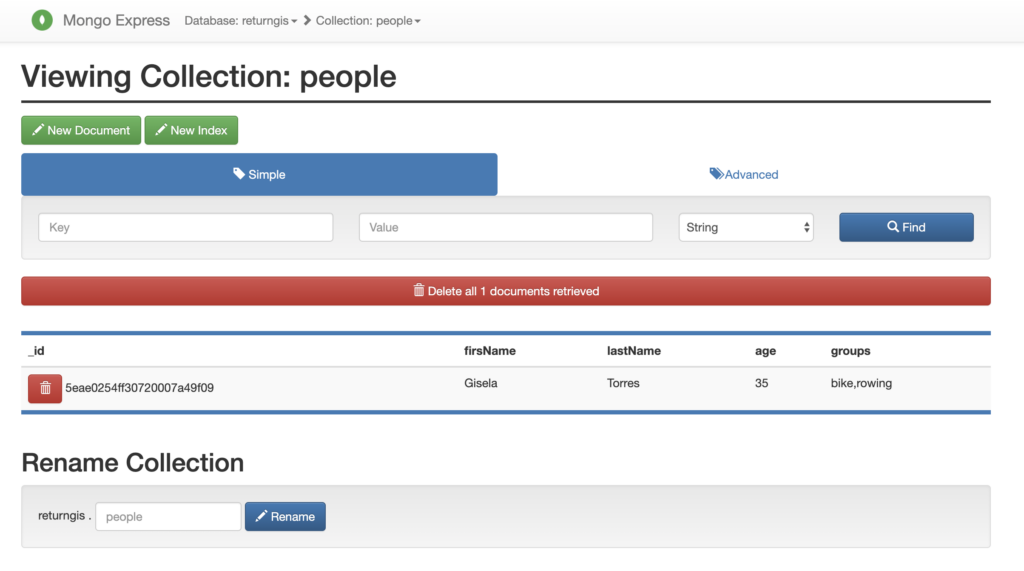
Después, conéctate a uno de los nodos secundarios y comprueba que el contenido se ha replicado satisfactoriamente a través de los siguientes comandos:
#Check mongo-1
kubectl exec -it mongo-1 mongo
rs.slaveOk()
show dbs
use returngis
db.people.find()
En mi caso la salida es la siguiente:
rs0:SECONDARY> rs.slaveOk()
rs0:SECONDARY> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
returngis 0.000GB
rs0:SECONDARY> use returngis
switched to db returngis
rs0:SECONDARY> db.people.find()
{ «_id» : ObjectId(«5eae0254ff30720007a49f09»), «firsName» : «Gisela», «lastName» : «Torres», «age» : 35, «groups» : [ «bike», «rowing» ] }
Otra de las pruebas que puedes hacer es que mongo-0, que es el primario dentro del clúster de Mongo, falle (eliminándolo por ejemplo).
kubectl delete pod mongo-0
Comprobarás que uno de los otros dos nodos se vuelve el primario, el eliminado vuelve a recrearse con el mismo nombre, asociado al mismo storage y volverá a pertenecer al replica set de Mongo (cuando se recupere) ya que su identidad no ha cambiado.
El código del ejemplo lo tienes en mi GitHub.
¡Saludos!