
Autoescalar tus aplicaciones en Kubernetes
Ahora que ya te he contado cómo desplegar tus pods a través de Jobs, CronJobs, Deployments, ReplicaSets (obvié los ReplicationControllers porque deberían caer en el deuso) y los StatefulSets, para terminar la semana quería mostrarte cómo de sencillo es autoescalar tus aplicaciones dentro de Kubernetes.
HorizontalPodAutoscaler
Para que una aplicación pueda aumentar o disminuir de manera automática sus réplicas necesitas crear un objeto llamado HorizontalPodAutoscaler. Este se encargará de subir y/o bajar el número de réplicas que necesita tu aplicación en cada momento en base a unos umbrales que establezcas.
Para este ejemplo voy a utilizar un despliegue de una página web en ASP.NET Core:

Esta tiene configurada durante su creación 3 réplicas. Ahora, para crear este objeto la forma más sencilla es a través del comando autoscale:

Este recuperará todas las métricas de los pods que componen tu despliegue y hará una operación aritmética para determinar si el número de pods actual es el adecuado, en base al porcentaje establecido para el umbral, en este caso del 30%. Para este ejemplo sólo me estoy basando en el estado de la CPU, pero también es posible combinarlo con la memoria, o solamente basarnos en esta.
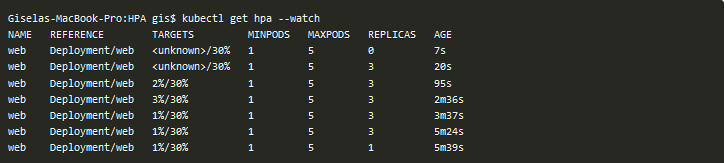
El proceso de muestreo no es inmediato sino que se revisan las métricas cada cierto tiempo (por defecto cada 15 segundos). Es por ello que inicialmente el valor de la operación que te contaba aparecerá como unknown y después de unos segundos comenzará a mostrar el valor actual del cálculo realizado:

De hecho, si esperas unos minutos comprobarás que de las 3 réplicas que habías establecido se quedará únicamente una al no tener actividad en la web:
Date cuenta de que para que un despliegue pueda autoescalar es necesario indicar los requests de los containers del pod que estableces para el HPA, ya que de lo contrario no funcionará. Te darás cuenta porque en los Eventos del Horizontal Pods Autoscaler aparecerá lo siguiente:

Ahora que ya tienes una web y un objeto HPA, vamos a intentar que el despliegue llegue hasta las 5 réplicas que tiene establecidas como máximo, haciendo que la CPU de los pods se dispare. Antes de ello, vigila en dos terminales separados lo siguiente:

Para estresar mis pods voy a utilizar Apache Benchmark con el siguiente comando:

Como ves, le he pedido 50.000 peticiones simulando 200 usuarios concurrentes. Igual me he pasado un poco pero tendrás tiempo más que de sobra para ver cómo se comporta el autoescalado:

También verás cómo el deployment ha ido ajustando el número de réplicas según la CPU iba aumentando o disminuyendo para tus pods:

Por último si revisas los eventos del HorizontalPodAutoscaler:

Podrás comprobar todas las subidas y bajas que ha tenido que realizar en base a las métricas recibidas de tus pods:

Si bien todo esto nos permite gestionar picos de manera automatizada, la versión estable, a día de hoy, de los HorizontalPodAutoscaler solo se puede basar en las métricas CPU y memoria. En muchos escenarios son más que suficientes pero en otros se requiere vigilar algo más. Por ejemplo, si tu aplicación es más propensa a tener cuellos de botella en la red, más que en la CPU o en la memoria, seguramente te interese valorar otras métricas. Por otro lado, también puede ocurrir que necesites tener en cuenta servicios externos, como pueden ser colas de mensajerías.
A partir de Kubernetes 1.6 se añade soporte para hacer uso de métricas personalizadas y externas a través de la versión autoscaling/v2beta2. En un próximo artículo te mostraré cómo hacerlo.
¡Saludos!